

It’s known that the presence of duplicate code has negative impacts on software development and maintenance. Indeed a major drawback is when an instance of duplicate code is changed for fixing bugs or adding new features, its correspondents have to be changed simultaneously.
The most popular reason of duplicate code is the Copy/Paste operations, and in this case the source code is exactly similar in two or more places , this practice is discouraged in many articles, books, and web sites.However, sometimes it’s not easy to practice the recommendations, and the developer chose the easy solution: the Copy/Paste method.
There are many tools to detect these kind of cloned code, CCFinderX is one of the interesting available open source tools. CCFinderX is a code-clone detector, which detects code clones (duplicated code fragments) from source files written in Java, C/C++, COBOL, VB, C#. It’s enable a user-side customization of a preprocessor, and providing an interactive analysis based on metrics.
Using the appropriate tool makes easy the detection of the duplicate code from the copy/paste operations, however there are some cases where cloned code are not trivial to detect.
Hidden duplicate code
Case1: Modified Copy/pasted code.
As described before the major problem of a copy/pasted code is when an instance of duplicate code is changed, its correspondents have to be changed simultaneously. Unfortunately it’s not always the case and the duplicate code instances became different.
To avoid these kind of hidden duplicate code, don’t hesitate to use a tool like CFinderX to discover the duplicate code instances, and at least tag them by adding comments if you don’t have time to refactor your code. This operation is very useful when a developer try to change a duplicate code instance, he will be noticed that other places has the same code. however if the developer is not informed, he will change only one place, and it will be very difficult in the future to detect the modified duplicate code.
Case 2: Similar functionality
The copy/paste operations is not the only origin of duplicate code, another reason is when a similar functionality is implemented.
Here’s from wikipedia a brief description of this second duplicate code origin:
Functionality that is very similar to that in another part of a program is required and a developer independently writes code that is very similar to what exists elsewhere. Studies suggest, that such independently rewritten code is typically not syntactically similar.
Tracking hidden duplicate code:
In case of duplicate code not exactly the same, no tool could give you a reliable results, it could report only suspicious duplicate code, and it’s the responsibility of developers to check if it really concern a cloned code or just a false positive result.
Each tool uses a specific algorithm to track these kind of duplicate code, we didnt test any of these tools but I think that most of them could be interesting to check at least once, it could give you some interesting results that could help you to improve the design and implementation of your code, as we will discover later in this post.
In our case we will use an algorithm which consists in defining sets of methods that are using the same members, i.e calling the same methods, reading the same fields, writing the same fields. We call these sets, suspect-sets. Suspect-sets are sorted by the number of same members used.
CppDepend implements this algorithm as a CppDepend Power-Tool. Power-Tools are a set of open-source tools based on CppDpend.API. The source code of Power-Tools can be found in $CppDependInstallPath$\ CppDepend.PowerTools.SourceCode\ CppDepend.PowerTools.sln.
Let’s discover the efficiency of this algorithm by searching the duplicate code in the Irrlicht 3D engine code base.
Case study: Irrlicht 3D engine
The Irrlicht Engine is an open-source high-performance realtime 3D engine written in C++. It is completely cross-platform.
Here are two of the suspicious duplicate code detected:
1- Exact code duplicate
In this case 18 methods detected are using the same 3 methods, reading the same 2 fields and writing same 9 fields.
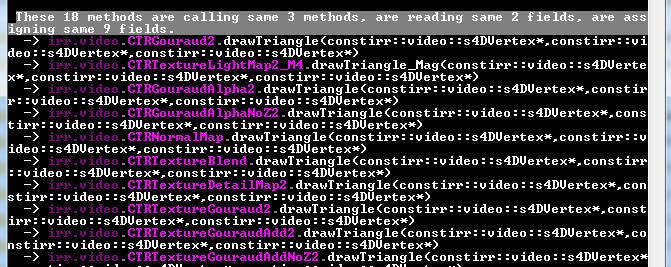
After checking the source code of these methods, it concern the exact code duplicated, however other tools are more interesting to detect these kind of duplicate, and the algorithm used has no added value when it concern the exact cloned code.
2- Similar functionality
Here’s a second suspicious duplicate code, it concern four methods using the same 11 methods, reading the same 6 fields and writing the same 2 fields.
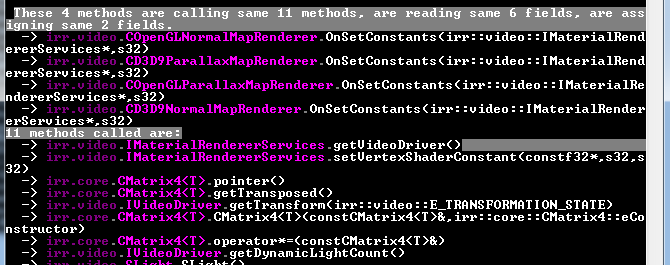
After checking These four methods source code, it’s not exactly the same code. However, they implement an unique layout algorithm. So here I’d vote for a factorization.
To explain better this case here’s a relation between the classes concerned by the duplicate code:
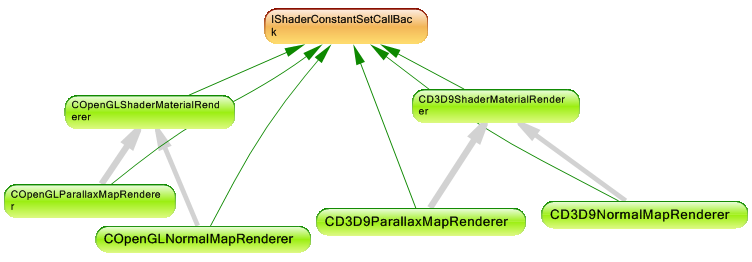
OnSetConstants is declared in the IShaderConstantSetCallBack interface and implemented by all the derived classes. All the four implementations has the same layout algorithm and in such cases the template method pattern is a good solution to refactor the existing implementation.
When testing this algorithm in many C++ open source projects we had very surprised that many duplicate code are similar to this case, and the template method pattern is rarely used.
Conclusion
Tracking duplicate code is very useful to improve both the implementation and the design of your projects. Fortunately many tools exist to detect the cloned code, and it’s recommended to execute periodically one of these tools and at least tag the duplicate instances.