

The Task Scheduler schedules and coordinates tasks at run time. A task is a unit of work that performs a specific job. The Task Scheduler manages the details that are related to efficiently scheduling tasks on computers that have multiple computing resources.
Windows OS provides a preemptive kernel-mode scheduler, it’s a round-robin, priority-based mechanism that gives every task exclusive access to a computing resource for a given time period, and then switches to another task.Although this mechanism provides fairness (every thread makes forward progress), it comes at some cost of efficiency.For example, many computation-intensive algorithms do not require fairness. Instead, it is important that related tasks finish in the least overall time. Cooperative scheduling enables an application to more efficiently schedule work.
Cooperative scheduling is a mechanism that gives every task exclusive access to a computing resource until the task finishes or until the task yields its access to the resource.
The user-mode cooperative scheduler enables application code to make its own scheduling decisions. Because cooperative scheduling enables many scheduling decisions to be made by the application, it reduces much of the overhead that is associated with kernel-mode synchronization.
The Concurrency Runtime uses cooperative scheduling together with the preemptive scheduler of the operating system to achieve maximum usage of processing resources.
Scheduler Design
The concurrency runtime provides the interface Scheduler to implement a specific scheduler adapted to application needs.
Let’s discover classes implementing this interface, for that we can execute the following CQL request:
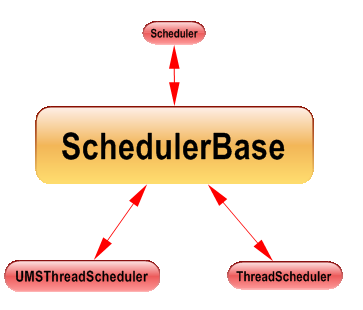
The concurrency runtime provides two implementations of scheduler, ThreadScheduler and UMSThreadScheduler.
The scheduler as shown by the following dependency graph, reference many abstrac classes to acheive its goal:
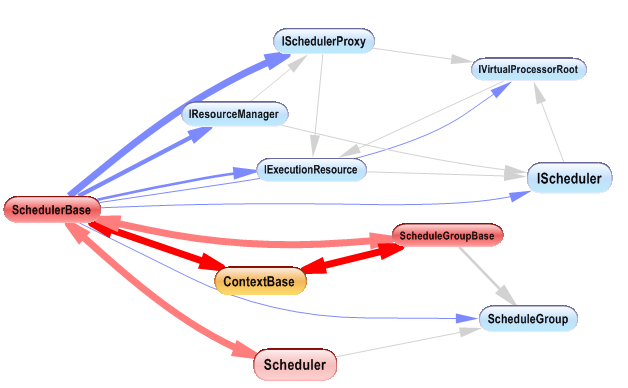
Let’s discover the role of each abstract class used by the scheduler, for that we will discuss its responsibilities.
There are three major responsibilities assigned to the Task Scheduler:
1) Getting Resources(Processors, Cores, Memory):
When the scheduler is created it ask for resources from runtime resource manager as explained in this article.
The scheduler communicates with the resource manager using IResourceManager, ISchedulerProxy and IScheduler interfaces.
When creating the scheduler we can specify its policy.
The Concurrency::PolicyElementKey enumeration defines the policy keys that are associated with the Task Scheduler.
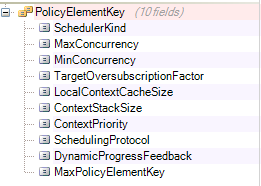
Here’s an article explaining the utility of each policy key, and the default value of each key.
Here’s a dependency graph to show what happens when we create a scheduler:

The concurrency runtime create a default scheduler if no scheduler exists by invocking GetDefaultScheduler method, and a default policy is used.
The Task Scheduler enables applications to use one or more scheduler instances to schedule work, and an application can invoke Scheduler::Create to add another scheduler that uses a specific policy.
The following collaborations between the scheduler and resource manager shows the role of each interface concerned by the allocation.
– Ask for resource allocation:
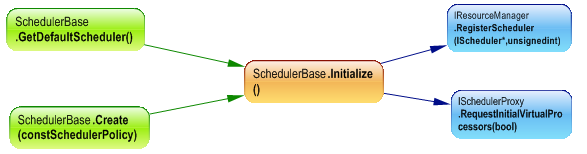
– Getting resources from resource manager:

2) Manage the task queues:
When Schedeluer is created, tasks could be assigned to it to be executed, the Scheduler store tasks into queues.to enforce the cohesion of classes, the queues are not managed directly by the ThreadScheduler class but by ScheduleGroupBase class.
A schedule group affinitizes, or groups, related tasks together. Every scheduler has one or more schedule groups. Use schedule groups when you require a high degree of locality among tasks, for example, when a group of related tasks benefit from executing on the same processor node.
As shown in the following graph, the runtime provides two kind of ScheduleGroup: FairScheduleGroup and CacheLocalScheduleGroup, choosing between thoses two groups as it will be explained later impact the algorithm of choosing the next task to execute by the scheduler.
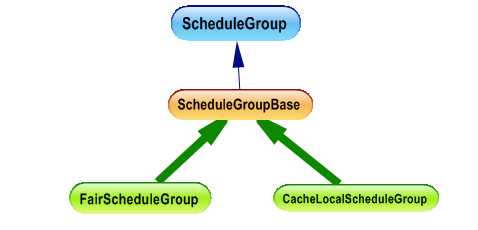
Every Scheduler has a default schedule group for every scheduling node.The runtime creates one scheduling node for every processor package or Non-Uniform Memory Architecture (NUMA) node. If you do not explicitly associate a task with a schedule group, the scheduler chooses which group to add the task to.
As shown in the following dependency graph , The schedulingRing is responsable of managing Scheduler Groups, it contains a list of groups and create them.
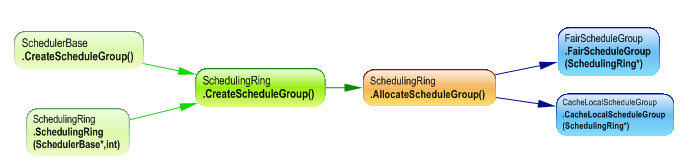
The Schedule group contains three kind of queues:
1) FIFO Queue
This queue contains lightweight tasks, a lightweight task resembles the function that you provide to the Windows API CreateThread function. Therefore, lightweight tasks are useful when you adapt existing code to use the scheduling functionality of the Concurrency Runtime.
A lighweight task is represented by RealizedChore class, and the FIFO queue of the schedule group is represented by the field m_realizedChores.
Let’s search for methods using directly this queue:
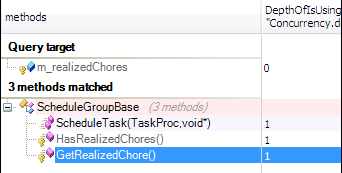
So we can add a lightweight task to the group by invoking ScheduleGroupBase::ScheduleTask or Scheduler::ScheduleTask.

Here’s an interesting article talking about lighweight tasks.
2)Work Stealing queue:
There’s only one FIFO queue associated to the schedule group, but the schedule group reference a list of work sealing queues, for each worker thread there’s a local queue associated with it.
A thread that is attached to a scheduler is known as an execution context, or just context, so actually this local queue is associated to Context class.
The Context class provides a programming abstraction for an execution context and offer the ability to cooperatively block, unblock, and yield the current context.
And to be sure that only the Context create this kind of queue, let’s search of the methods accessing directly to m_workQueues field.
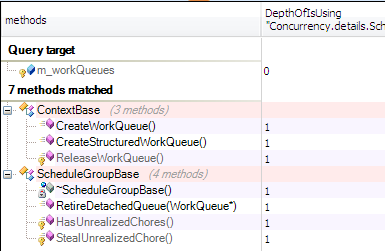
The context is responsable of creating this queue, and for each context there’s a local work stealing queue associated to it.
To illustrate the behavior of the work-stealing algorithm, let’s supposethat we have two worker thread allocated to the scheduler.
As explained before for each worker thread there’s a local queue associated with it.

Three tasks in the queue Worker Thread 1, tasks 3 and 4 are waiting to be executed while the 5 is running.

The Dispatch method finds that there is nothing in the queue, so the task 3 is moved, or “stolen” from its original queue, to be distributed the worker thread available.

How we can create a task managed by work stealing queue? for that let’s search for methods indirectly invocking the CreateWorkQueue method.
As shown in this dependency graph, this kind of task could be created by using task_group class.

Using task_group to add new task is more better than using Sheduler::ScheduleTask to create a lighweight task, indeed the work stealing algorithm optimize better the using of virtual processors allocated to the scheduler.
However, ScheduleTask could be better to migrate easilly from the existing code using CreateThread API.
3)Unblocqued Context queue:
The Context class lets you block or yield the current execution context. Blocking or yielding is useful when the current context cannot continue because a resource is not available.
The Context::Block method blocks the current context. A context that is blocked yields its processing resources so that the runtime can perform other tasks. The Context::Unblock method unblocks a blocked context.
When a context is unblocked and it’s available to be executed , it’s add to runnable context queue, this queue is represented by the field m_runnableContexts.
Here’s a dependency graph showing some cases where the context is added to runnable queue:

So the context is added to the queue when it’s unblocked or a virtual processor is retired from the scheduler.
3)Dispatching Tasks:
The scheduler try to search for work to execute, a work could be:
- Unblocked context.
- Lightweight task.
- Task in work stealing queues.
And as explained before all these works are stored in queues managed by Schedule groups, and each group is managed by a scheduling ring.
When a virtual processor is allocated to the scheduler a ThreadProxy class is created and associated to this processor. and after the creation, the Dispatch method of the ThreadProxy is invoked.
As shown in the following dependency graph and as explained before the concurrency runtime use abstract classes to enforces low coupling, and the real dispatch invoked depends of the implementation choosed by the runtime, this choice is given by the scheduler policy.

The concrete implementation of Dispatch invoke Dispatch Method of the execution context.
Here’s a dependec graph showing methods invocked by a concrete implementation of Context::Dispatch method:
So the algorithm of searching the next work to execute is implemented by WorkSearchContext class.
Let’s discover all classes used directly by WorkSearchContext to acheive its responsability:

The responsability of WorkSearchContext is to give us a WorkItem to execute, it could be InternalContextBase, RealizedChore or _UnrealizedChore.
To understand better the collaboration between these classes , let’s search for methods used directly by WorkSearchContext:

So the WorkSearchContext iterate on SchedulingRing and SheduleGroup classes by using SchedulerBase methods.
And for each ScheduleBase we search for RunnableContext, realizedChore or UnrealizedChore.
The WorkSearchContext class is creaed by the VirtualProcessor class, and as shown in the following dependency graph, the algorithm used is specified when the VirtualProcessor is initialized, and for that, it ask the Scheduler for the SchedulingProtocol which describe the scheduling algorithm that will be utilized for the scheduler.

The WorkSearchContext will be notified by the algorithm to use by passing it a value from Algorithm enum.

So two algorithmes are implemented by this class to find a work:
– Cache Local algorithm:
This algorithm will look for runnables context within the current schedule group, then realized chores then unrealized chores, if there’s no more work in the curent schedule group it look for the next group in the same shedule ring, and when it finish all works in the current schedule ring it look in the next schedule ring.
So the scheduler prefers to continue to work on tasks within the current schedule group before moving to another schedule group.
This algorithm is implemented by WorkSearchContext::SearchCacheLocal method, and as show by this dependency graph, this method search invoke other methods to search for runnable contexts, RealizedChore or _UnrealizedChore.

Another specificity of this algorithm is that the unblocked contexts are cached per virtual-processor and are typically scheduled in a last-in first-out (LIFO) fashion by the virtual processor which unblocked them.
And to verify this behavior, here’s a dependency graph of methods invocked when searching for runnable context:

This algorithm is the default algorithm choosen by the scheduler if no one is specified.
– Fair algorithm:
In this case, the scheduler prefers to round-robin through schedule groups after executing each task. Unblocked contexts are typically scheduled in a first-in-first-out (FIFO) fashion. Virtual processors do not cache unblocked contexts.
This algorithm is implemented by WorkSearchContext::SearchFair method, and as show by this dependency graph, this method search invoke other methods to search for runnable contexts, RealizedChore or _UnrealizedChore.
