

The POCO C++ Libraries are a collection of open source class libraries for developing network-centric, portable applications in C++.
POCO stands for POrtable COmponents. The libraries cover functionality such as threads, thread synchronization, file system access, streams, shared libraries and class loading, sockets and network protocols (HTTP, FTP, SMTP, etc.), and include an HTTP server, as well as an XML parser with SAX2 and DOM interfaces and SQL database access.
The modular and efficient design and implementation makes the POCO C++ Libraries well suited for embedded development.
Let’s explore a code snippet from the POCO source code:
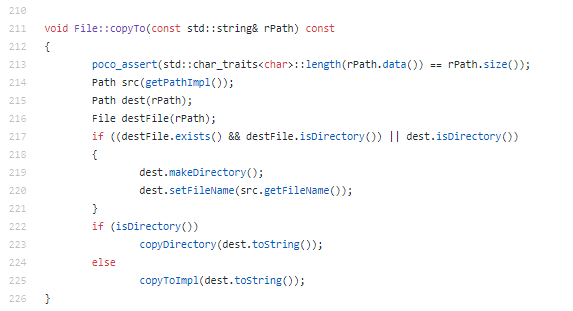
This implementation is characterized by:
- The function has few parameters.
- Assert technique is used to check if the entries are OK.
- The variable naming is easy to understand.
- The method is short.
- No extra comments in the body.The code explains itself.
- The function body is well indented.
- The well validated STL library is used when needed.
If we navigate across the POCO source code we can remark the coherence of the implementation. The same best practices rules are applied to each function.
Let’s take a look inside POCO using CppDepend and discover some facts about its design and its implementation .
DESIGN
ABSTRACT VS INSTABILITY
Robert C.Martin wrote an interesting article about a set of metrics that can be used to measure the quality of an object-oriented design in terms of the interdependence between the subsystems of that design.
Here’s from the article what he said about the interdependence between modules:
What is it that makes a design rigid, fragile and difficult to reuse. It is the interdependence of the subsystems within that design. A design is rigid if it cannot be easily changed. Such rigidity is due to the fact that a single change to heavily interdependent software begins a cascade of changes in dependent modules. When the extent of that cascade of change cannot be predicted by the designers or maintainers the impact of the change cannot be estimated. This makes the cost of the change impossible to estimate. Managers, faced with such unpredictability, become reluctant to authorize changes. Thus the design becomes rigid.
And to fight the rigidity he introduce metrics like Afferent coupling, Efferent coupling, Abstractness, Instability and the “distance from main sequence” and the “Abstractness vs Instability” graph.
The “Abstractness vs Instability” graph can be useful to identify the projects difficult to maintain and evolve. Here’s the “Abstractness vs Instability” graph of the POCO library:
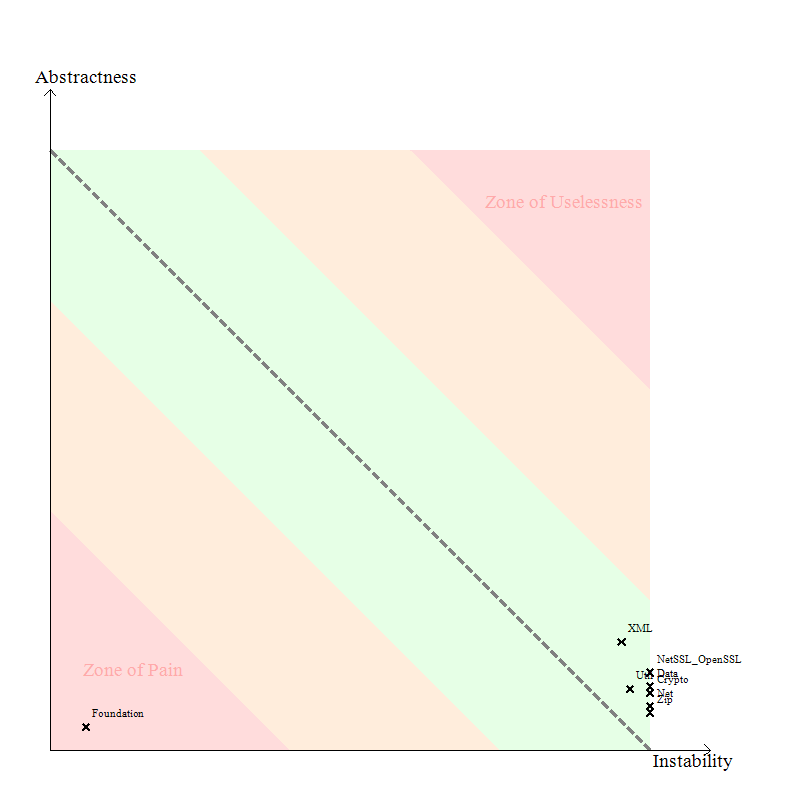
The idea behind this graph is that the more a code element of a program is popular, the more it should be abstract. Or in other words, avoid depending too much directly on implementations, depend on abstractions instead. By popular code element I mean a project (but the idea works also for packages and types) that is massively used by other projects of the program.
It is not a good idea to have concrete types very popular in your code base. This provokes some Zones of Pains in your program, where changing the implementations can potentially affect a large portion of the program. And implementations are known to evolve more often than abstractions.
The main sequence line (dotted) in the above diagram shows the how abstractness and instability should be balanced. A stable component would be positioned on the left. If you check the main sequence you can see that such a component should be very abstract to be near the desirable line – on the other hand, if its degree of abstraction is low, it is positioned in an area that is called the “zone of pain”.
Only the Fondation project is inside the zone of pain , it’s normal because it’s very used by other projects.
[adrotate banner=”3″]
INHERITANCE
Multiple inheritance increase the complexity and it’s better to use it carefully.
Let’s search for all classes with many base classes.
The blue rectangles represent the result.
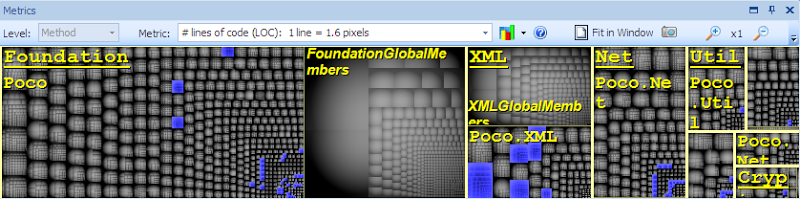
Only few classes derived from more than one class.
TYPE COHESION
The single responsibility principle states that a class should have more than one reason to change. Such a class is said to be cohesive. A high LCOM value generally pinpoints a poorly cohesive class. There are several LCOM metrics. The LCOM takes its values in the range [0-1]. The LCOMHS (HS stands for Henderson-Sellers) takes its values in the range [0-2]. Note that the LCOMHS metric is often considered as more efficient to detect non-cohesive types. LCOMHS value higher than 1 should be considered alarming.
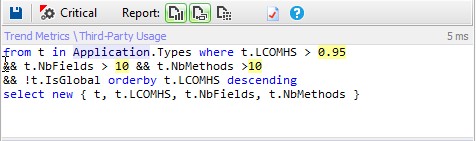
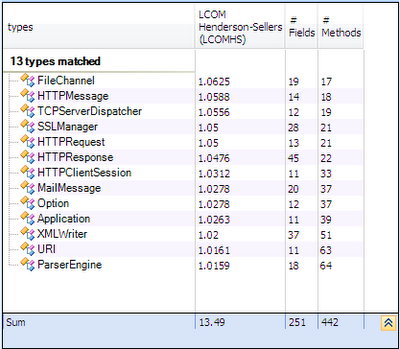
Only 1% of types are considered as no cohesive.
EFFERENT COUPLING
The Efferent Coupling for a particular type is the number of types it directly depends on.
Types where TypeCe > 50 are types that depends on too many other types. They are complex and have more than one responsability. They are good candidate for refactoring.
Let’s execute the following CQLinq request.
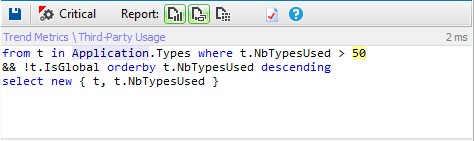
And the result is empty so no class has many responsibilities.
TYPES MOST USED
It’s very interesting to know which types are most used,for that we can use the TypeRank metric.
TypeRank values are computed by applying the Google PageRank algorithm on the graph of type’s dependencies. A homothety of center 0.15 is applied to make it so that the average of TypeRank is 1.
Types with high TypeRank should be more carefully tested because bugs in such types will likely be more catastrophic.
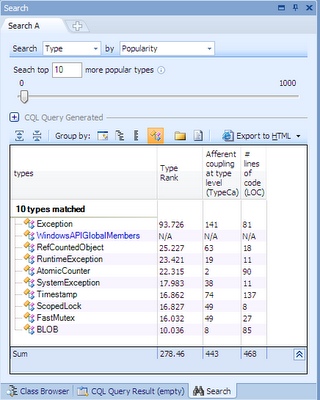
Let’s search for types most used and complex.
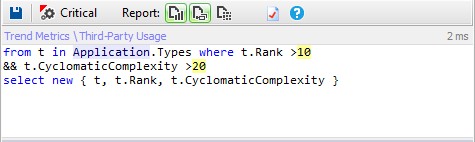
The result is empty so no class is very used and complex.
LAYERING AND LEVEL METRIC
This post explain the level metric and how to exploit it to improve design.
Let’s search dependency cycles for that we can execute the following CQLinq request:
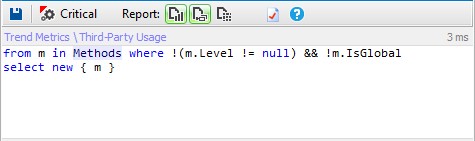

Only few methods has dependency cycle, let’s take for example the Zip project and look to its dependency graph.
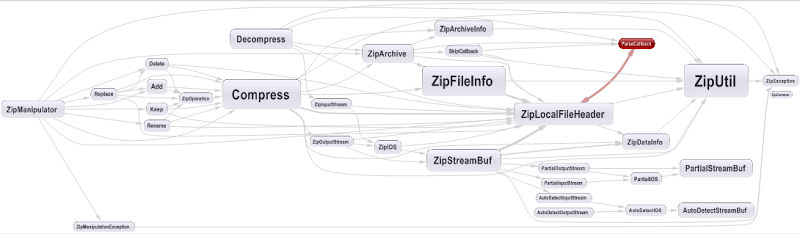
Only 1 dependency cycle exist in this project.
POCO Implementation
NUMBER OF LINE OF CODE
Methods with many number of line of code are not easy to maintain and understand, let’s search for the methods with more than 60 lines.
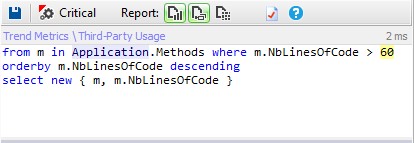
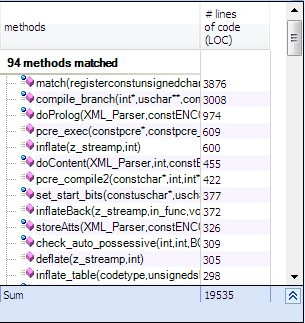
Less than 1% of methods has more than 60 lines.
[adrotate banner=”3″]
CYCLOMATIC COMPLEXITY
Cyclomatic complexity is a popular procedural software metric equal to the number of decisions that can be taken in a procedure.
Let’s execute the following CQLinq request to detect methods to refactor.
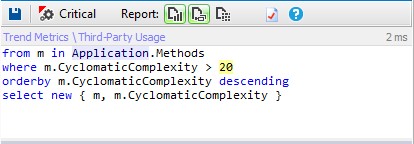
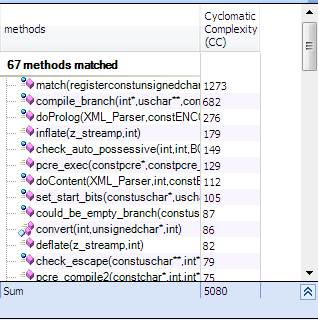
So only 1% of methods can be considered as complex.
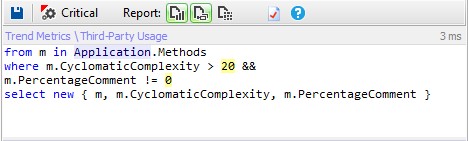
Which methods are complex and not enough commented?
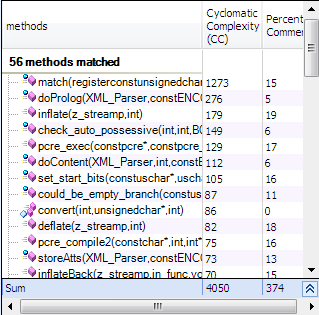
METHODS WITH MANY VARIABLES
Methods where NbVariables is higher than 8 are hard to understand and maintain. Methods where NbVariables is higher than 15 are extremely complex and should be split in smaller methods (except if they are automatically generated by a tool).
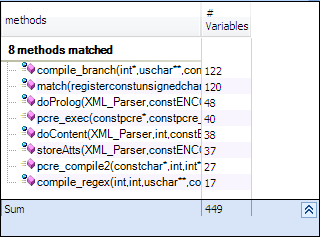
Only 8 methods has too many variables.
TYPES WITH MANY METHODS AND FIELDS
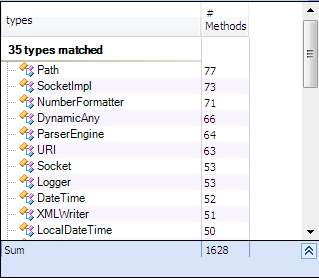
Only 3% of types has many methods.
And we can do the same search for fields
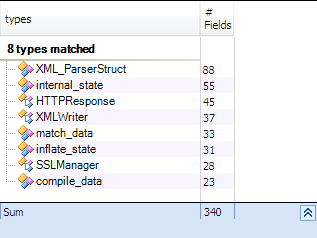
Less than 1% of types has many fields.
We can say that POCO is well implemented, few methods are considered as complex, the types are simple with few methods and fields and it’s well commented.
[adrotate banner=”3″]