

It’s proven that Clang is a mature compiler For C and C++ as GCC and Microsoft compilers, but what makes it special is the fact that it’s not just a compiler. It’s also an infrastructure to build tools. Thanks to its library based architecture which makes the reuse and integration of functionality provided more flexible and easier to integrate into other projects.
Clang Design:
Like many other compiler design, Clang compiler has three phase:
- The front end that parses source code, checking it for errors, and builds a language-specific Abstract Syntax Tree (AST) to represent the input code.
- The optimizer: its goal is to do some optimisaion on the AST generated by the front end.
- The back end : that generate the final code to be executed by the machine, it depends of the target.

What the difference between Clang and the other compilers?
The most important difference of its design is that Clang is based on LLVM , the idea behind LLVM is to use LLVM Intermediate Representation (IR), it’s like the bytecode for java.
LLVM IR is designed to host mid-level analyses and transformations that you find in the optimizer section of a compiler. It was designed with many specific goals in mind, including supporting lightweight runtime optimizations, cross-function/interprocedural optimizations, whole program analysis, and aggressive restructuring transformations, etc. The most important aspect of it, though, is that it is itself defined as a first class language with well-defined semantics.
With this design we can reuse a big part of the compiler to create other compilers, you can for example just change the front end part to treat other languages.

It’s very interesting to go inside this powerful game engine and discover how it’s designed and implemented. C++ developers could learn many good practices from its code base.
Let’s XRay its source code using CppDepend and CQLinq to explore some design and implementation choices of its developement team.
1- Modularity:
1-1 Modualrity using Libraries
A major design concept for clang is its use of a library-based architecture. In this design, various parts of the front-end can be cleanly divided into separate libraries which can then be mixed up for different needs and uses. In addition, the library-based approach encourages good interfaces and makes it easier for new developers to get involved (because they only need to understand small pieces of the big picture).
The DSM (Dependency Structure Matrix) is a compact way to represent and navigate across dependencies between components. A non-empty DSM Cell contain a number. This number represent the strengths of the coupling represented by the cell. The coupling strength can be expressed in terms of number of members/methods/fields/types or namespaces involved in the coupling. The DSM could also show us the dependency ycles between the libraries.
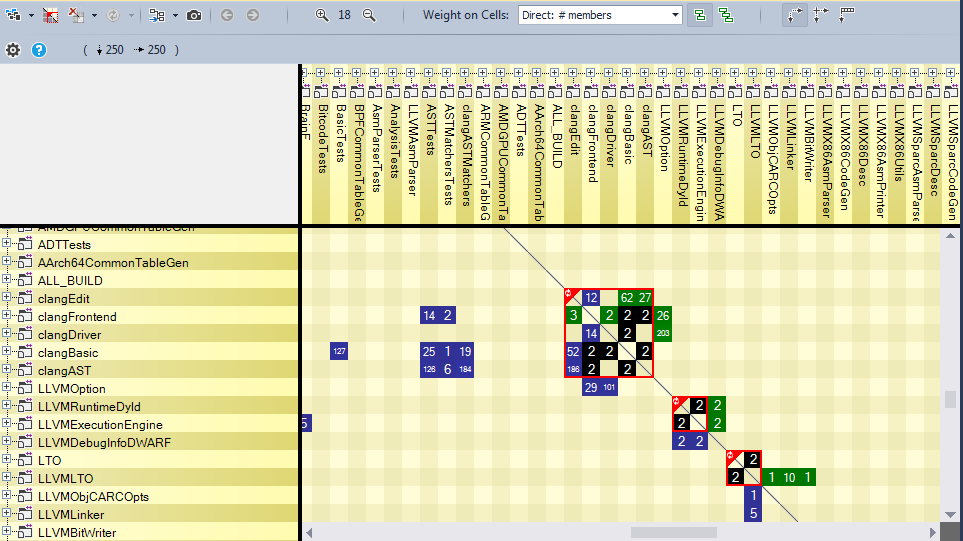
This dependency graph shows the libraries used directly by clang,
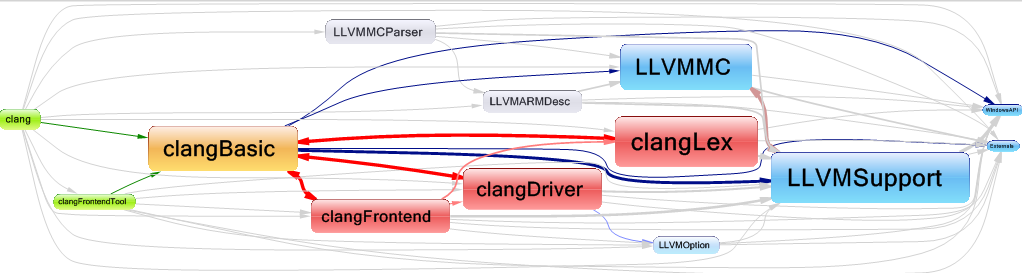
As we can remark there are three dependency cycles between the libraries clangBasic/clangFrontEnd, clangBasic/clangDriver and clangBasic/clangLex. It’s recommended to remove any dependency cycle between the libraries to makes the code more readable and maintainable.
It’s normal that clangFrontend uses clangBasic, However why the clangFrontend uses the clangBasic library?
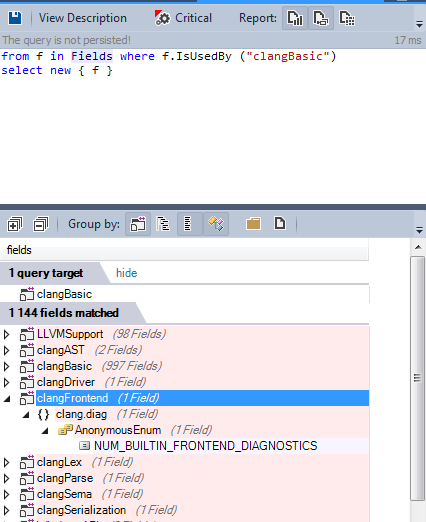
Only one enum field is the origin of this dependency cycle, the code could be refactored and the dependency could be easily removed.
1-2 Modualrity using namespaces
In C++ the namespaces are also used to modularize the code base and for the LLVM/clang they are used for three main reasons:
- Many namespaces contains only enums as shown by this following CQLinq query, which gives us the ones containing only enums
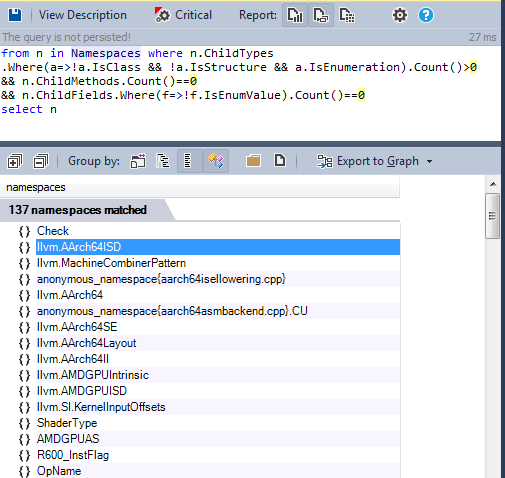
In a large project, you would not be guaranteed that two distinct enums don’t both called with the same name. This issue was resolved in C++11, using enum class which implicitly scope the enum values within the enum’s name. The code could be refactored in the near future to use C++11 enum classes.
- Anonymous namespace: Namespace with no name avoids making global static variable. The “anonymous” namespace you have created will only be accessible within the file you created it in. Here’s the list of all anonymous namespaces used:
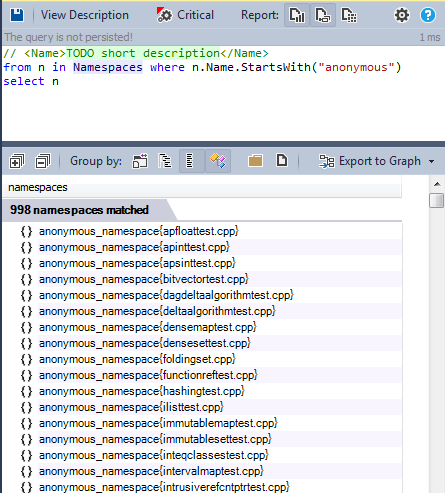
- Modularize the code base: Let’s search for all the not anonymous ones:
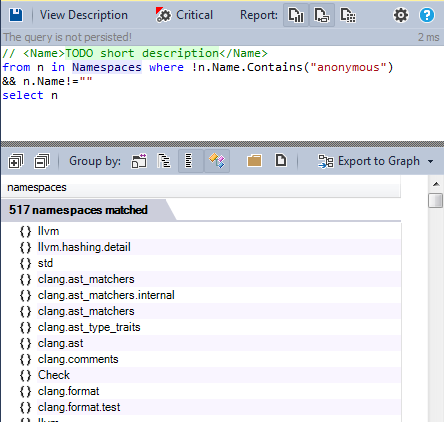
The namespaces represents a good solution to modularize the application, LLVM/clang defines more than 500 namespaces to enforces its modularity, which makes the code more readable and maintanble.
2- Paradigm used:
C++ is not just an object-oriented language. As Bjarne Stroustrup points out, “C++ is a multi-paradigmed language.” It supports many different styles of programs, or paradigms, and object-oriented programming is only one of these. Some of the others are procedural programming and generic programming.
2-1 Procedural Paradigm
2-1-1 Global functions
Let’s search for all global functions defined in the LLVM/Clang source code:
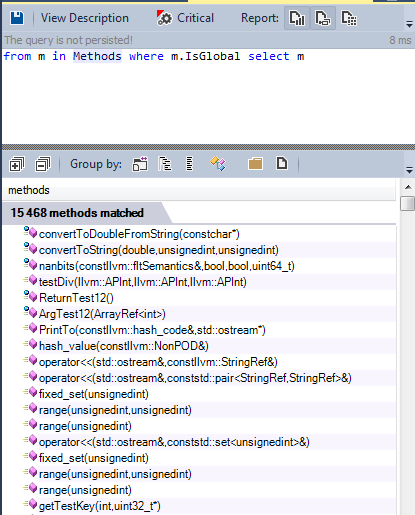
We can classify these functions in three categories:
1 – Utility functions: For example many functions concern the conversion from type to another.
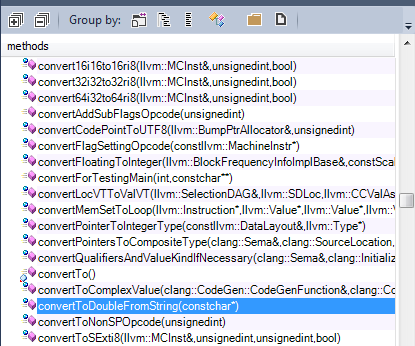
2 – Operators: Many operators are defined as shown by the result of this CQLinq query:
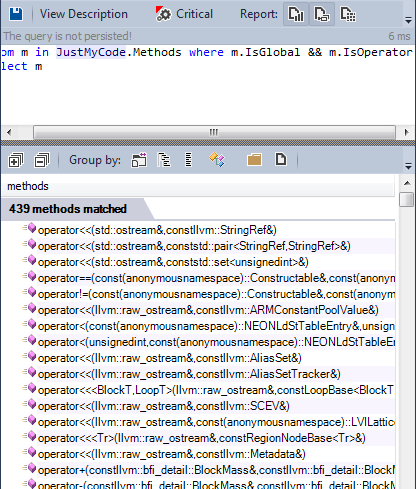
Almost all kind of operators are implemented in the llvm/clang source code.
3 – Functions related to the compiler logic: Many global functions containing some compiler traitments are implemented.
Maybe these kind of functions could be grouped by category as static methods into classes. Or grouped in namespaces.
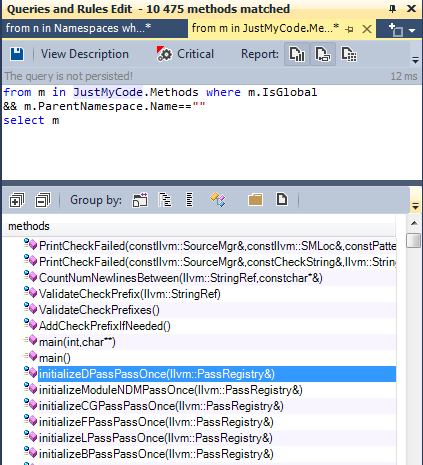
2-1-2 Static global functions:
It’s a best practice to declare a global function as static unless you have a specific need to call it from another source file.
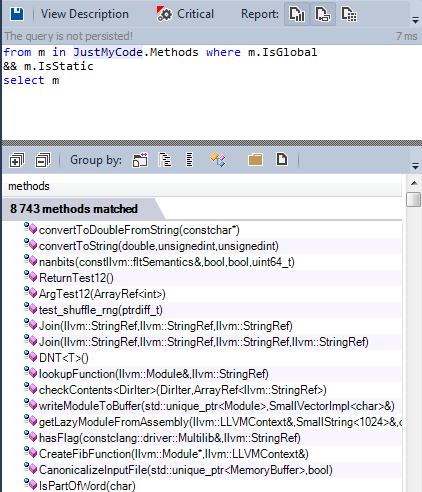
Almost all the global functions are declared as static.
2-1-3 Global functions candidate to be static.
Global not exported functions, not defined in an anonymous namespace and not used by any method outside the file where it was defined. are a good candidates to be refactored to be static.
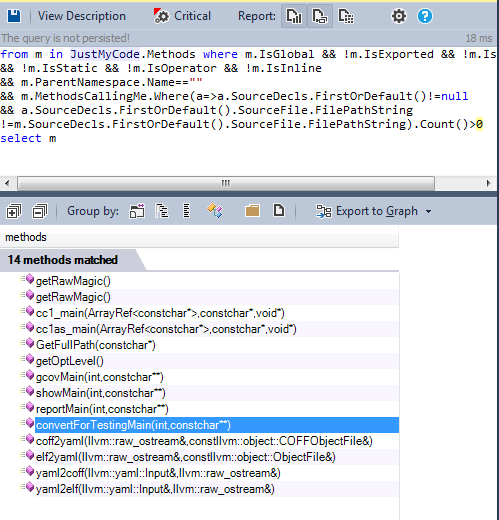
As we can observe only very few functions are candidates to be refactored to be static.
2-2 Object Oriented paradigm
2-2-1 Inheritance
In object-oriented programming (OOP), inheritance is a way to establish Is-a relationship between objects. It is often confused as a way to reuse the existing code which is not a good practice because inheritance for implementation reuse leads to Tight Coupling. Re-usability of code is achieved through composition (Composition over inheritance). Let’s search for all classes having at least one base class:
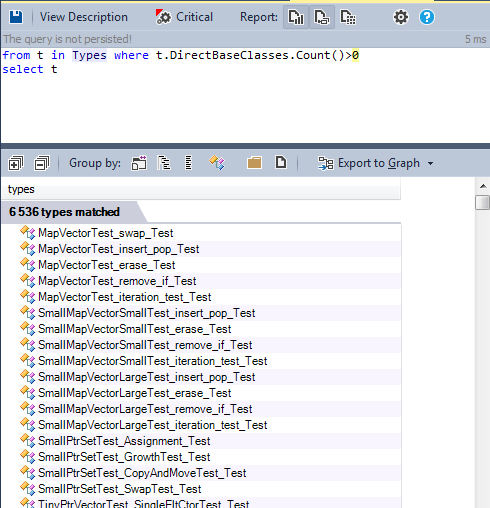
And to have a better idea of the classes concerned by this query, we can use the Metric View.
In the Metric View, the code base is represented through a Treemap. Treemapping is a method for displaying tree-structured data by using nested rectangles. The tree structure used in a CppDepend treemap is the usual code hierarchy:
- Projects contains namespaces.
- Namespaces contains types.
- Types contain methods and fields.
The treemap view provides a useful way to represent the result of a CQLinq request, the blue rectangles represent this result, so we can visually see the types concerned by the request.
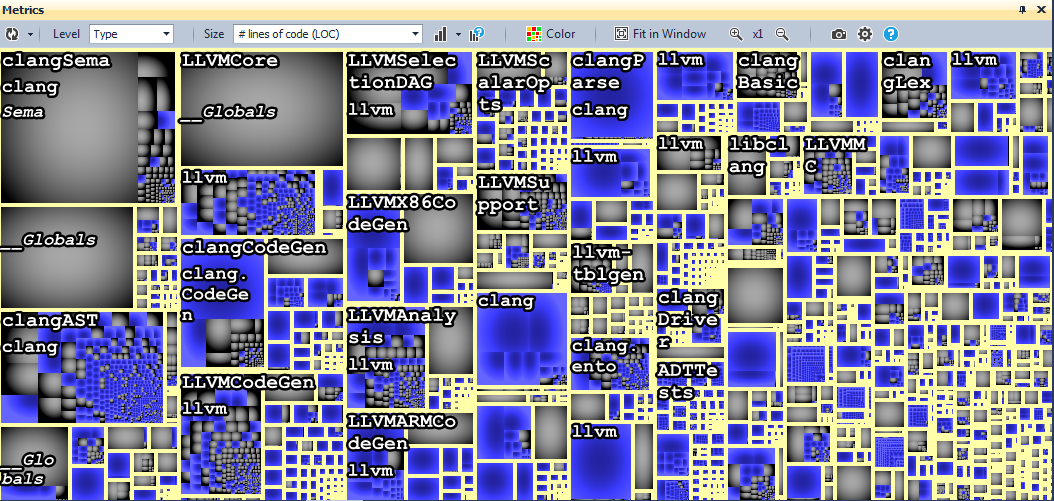
As we can observe, the inheritance is widely used in the llvm/clang source code.
Multiple Inheritance: Let’s search for classes inheriting from more than one concrete class.
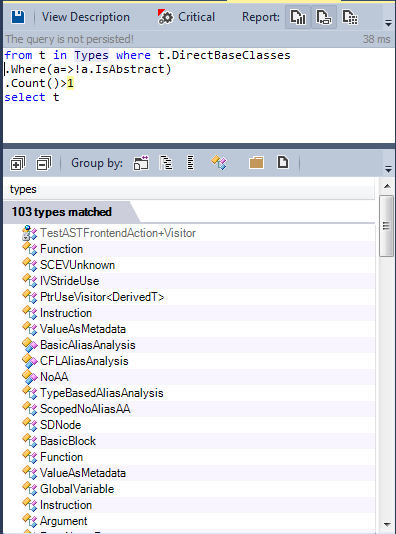
The multiple inheritance is not widely used,less than 1% of the classes inherit from more than one class.
2-2-2 Virtual methods
Let’s search for all virtual methods defined in the source code:
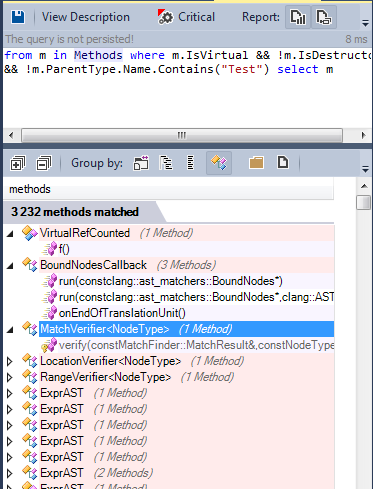
Many methods are virtual, and some of them are pure virtual:
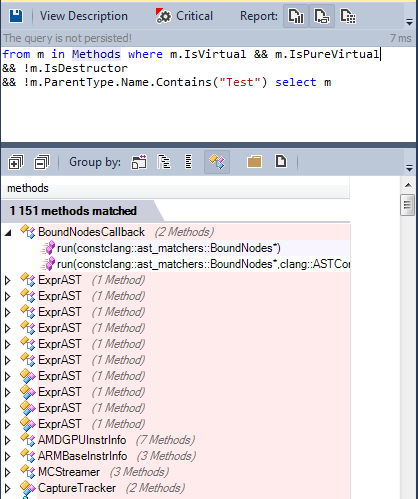
The OOP paradigm is widely used in the llvm/clang source code. What about the generic programming paradigm?
2-3 Generic Programming
C++ provides unique abilities to express the ideas of Generic Programming through templates. Templates provide a form of parametric polymorphism that allows the expression of generic algorithms and data structures. The instantiation mechanism of C++ templates insures that when a generic algorithm or data structure is used, a fully-optimized and specialized version will be created and tailored for that particular use, allowing generic algorithms to be as efficient as their non-generic counterparts.
2-3-1 Generic types:
Let’s search for all genric types defined in the engine source code:
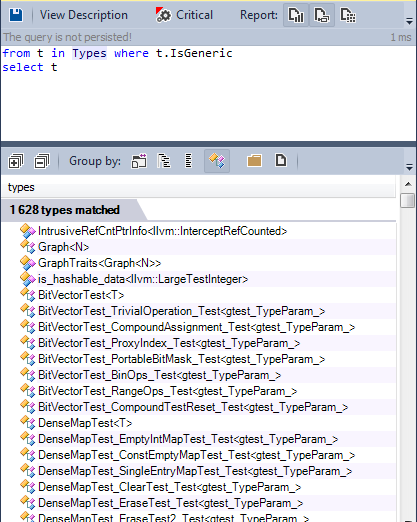
Many types are defined as generic. Let’s search for generic methods:
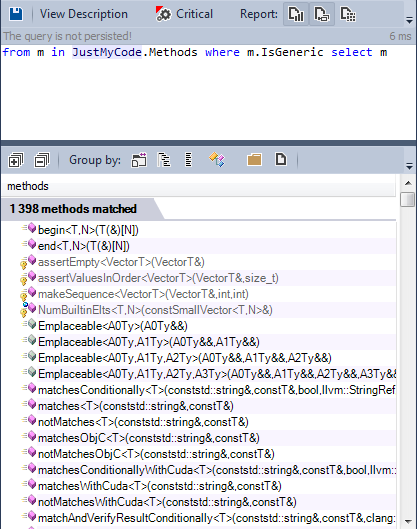
Less than 1% of methods are generic,
To resume the llvm/clang source code mix between the three pradigms.
3- PODs to define the data model
In object-oriented programming, plain old data (POD) is a data structure that is represented only as passive collections of field values (instance variables), without using object-oriented features. In computer science, this is known as passive data structure
Let’s search for the POD types in the source code
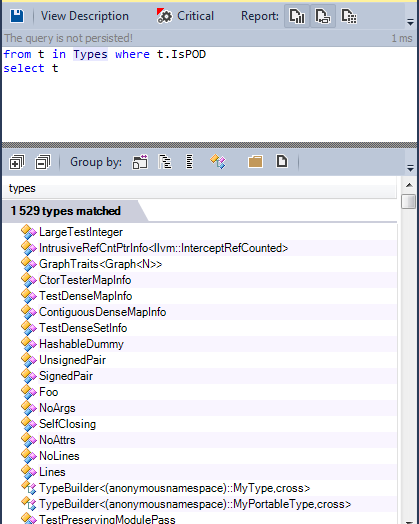
More than 1500 types are defined as POD types, many of them are used to define the compiler data model.
4- Gang Of Four design patterns
Design Patterns are a software engineering concept describing recurring solutions to common problems in software design. Gang of four patterns are the most popular ones. Let’s discover some of them used in the llvm/clang source code.
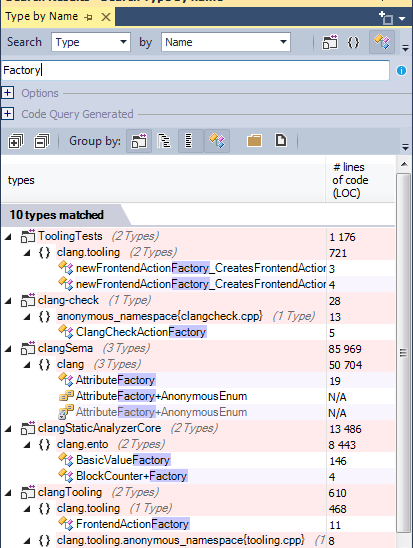
4-1 Factory
Using factory is interesting to isolate the logic instantiation and enforces the cohesion , here is the list of factories defined in the source code:
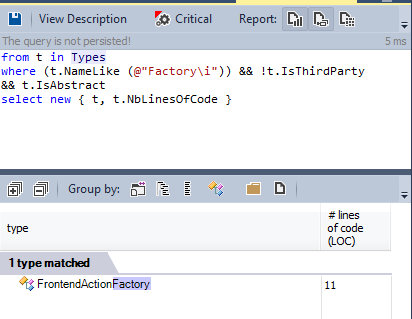
And here’s the list of the abstract ones:
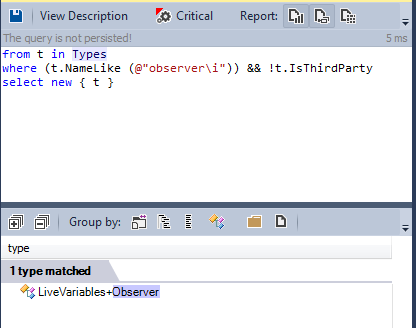
4-3 Observer
The observer pattern is a software design pattern in which an object maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods.
Only one obserer is defined in the source code:
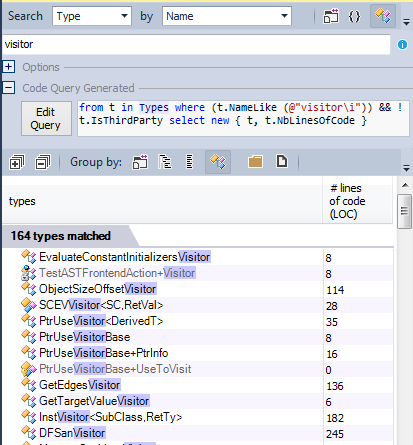
4-4 Visitor
The visitor pattern is the recommended pattern when we need to traverse a structure and do a specific treatement for each node of this structure.
In the llvm/clang source code, the visitor pattern is widely used:
5- Coupling and Cohesion
5-1 Coupling
Low coupling is desirable because a change in one area of an application will require fewer changes throughout the entire application. In the long run, this could alleviate a lot of time, effort, and cost associated with modifying and adding new features to an application.
Low coupling could be acheived by using abstract classes or using generic types and methods.
Let’s search for all abstract classes defined in the source code :
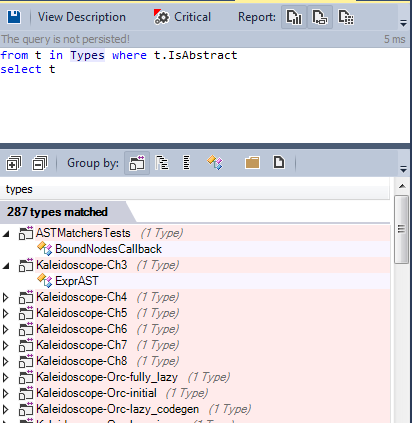
more than 280 types are declared as abstract. However the low coupling is also enforced by using generic types and generic methods.
Cohesion
The single responsibility principle states that a class should not have more than one reason to change. Such a class is said to be cohesive. A high LCOM value generally pinpoints a poorly cohesive class. There are several LCOM metrics. The LCOM takes its values in the range [0-1]. The LCOM HS (HS stands for Henderson-Sellers) takes its values in the range [0-2]. A LCOM HS value highest than 1 should be considered alarming. Here are to compute LCOM metrics:
LCOM = 1 – (sum(MF)/M*F)
LCOM HS = (M – sum(MF)/F)(M-1)
Where:
- M is the number of methods in class (both static and instance methods are counted, it includes also constructors, properties getters/setters, events add/remove methods).
- F is the number of instance fields in the class.
- MF is the number of methods of the class accessing a particular instance field.
- Sum(MF) is the sum of MF over all instance fields of the class.
The underlying idea behind these formulas can be stated as follow: a class is utterly cohesive if all its methods use all its methods use all its instance fields, which means that sum(MF)=M*F and then LCOM = 0 and LCOMHS = 0.
LCOMHS value higher than 1 should be considered alarming.
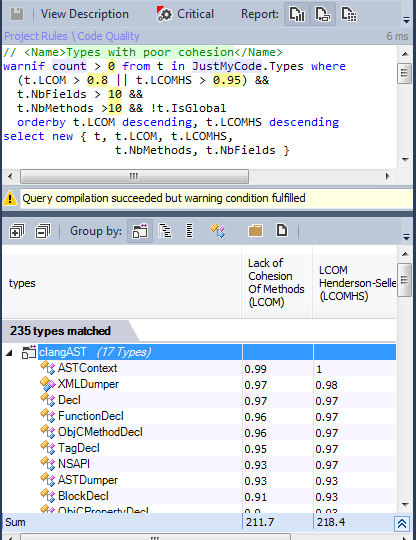
235 classes are concerned, maybe some classes could be refactored to improve their cohesion.
6- Immutability, Purity and side effect
6-1 Immutable types
Basically, an object is immutable if its state doesn’t change once the object has been created. Consequently, a class is immutable if its instances are immutable.
There is one important argument in favor of using immutable objects: It dramatically simplifies concurrent programming. Think about it, why does writing proper multithreaded programming is a hard task? Because it is hard to synchronize threads access to resources (objects or others OS resources). Why it is hard to synchronize these accesses? Because it is hard to guarantee that there won’t be race conditions between the multiple write accesses and read accesses done by multiple threads on multiple objects. What if there are no more write accesses? In other words, what if the state of the objects accessed by threads, doesn’t change? There is no more need for synchronization!
Another benefit about immutable classes is that they can never violate LSP (Liskov Subtitution Principle) , here’s a definition of LSP quoted from its wiki page:
Liskov’s notion of a behavioral subtype defines a notion of substitutability for mutable objects; that is, if S is a subtype of T, then objects of type T in a program may be replaced with objects of type S without altering any of the desirable properties of that program (e.g., correctness).
Here’s the list of immutable types defined in the source code:
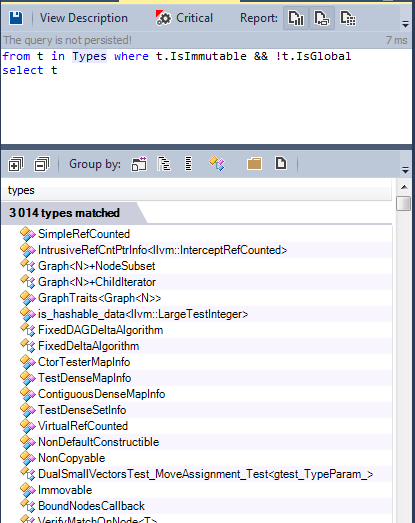
6-2 purity and side effect
The primary benefit of immutable types come from the fact that they eliminate side-effects. I couldn’t say it better than Wes Dyer so I quote him:
We all know that generally it is not a good idea to use global variables. This is basically the extreme of exposing side-effects (the global scope). Many of the programmers who don’t use global variables don’t realize that the same principles apply to fields, properties, parameters, and variables on a more limited scale: don’t mutate them unless you have a good reason.(…)
One way to increase the reliability of a unit is to eliminate the side-effects. This makes composing and integrating units together much easier and more robust. Since they are side-effect free, they always work the same no matter the environment. This is called referential transparency.
Writing your functions/methods without side effects – so they’re pure functions, i.e. not mutate the object – makes it easier to reason about the correctness of your program.
Here’s the list of all methods without side-effects
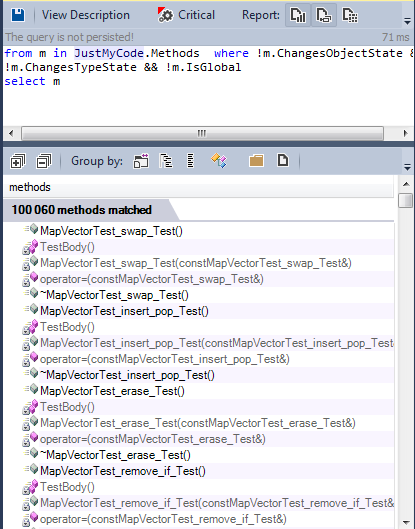
More than 100 000 methods are pure.
7- Implementation quality
7-1 Too big methods
Methods with many number of line of code are not easy to maintain and understand. Let’s search for methods with more than 60 lines.
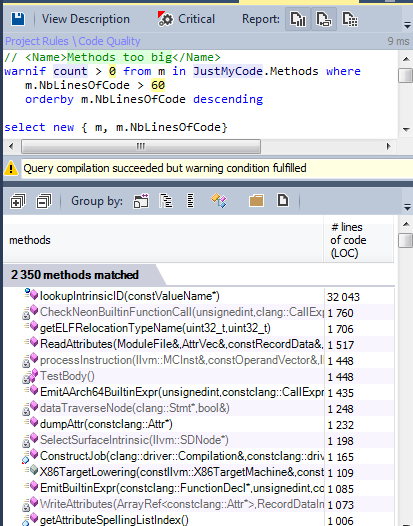
The llvm/clang source code contains more than 100 000 methods, so less than 2% could be considered as too big.
7-2 Methods with many parameters
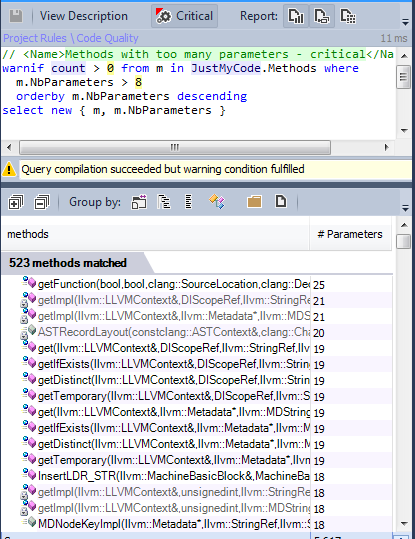
Few methods has more than 8 parameters.
7-3 Methods with many local variabless
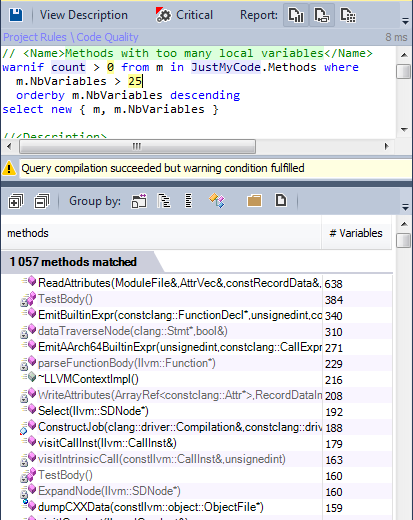
Less than 1% has many local variables.
7-4 Methods too complex
Many metrics exist to detect complex functions, NBLinesOfCode,Number of parameters and number of local variables are the basic ones.
There are other interesting metrics to detect complex functions:
- Cyclomatic complexity is a popular procedural software metric equal to the number of decisions that can be taken in a procedure.
- Nesting Depth is a metric defined on methods that is relative to the maximum depth of the more nested scope in a method body.
- Max Nested loop is equals the maximum level of loop nesting in a function.
The max value tolerated for these metrics depends more on the team choices, there’s no standard values.
Let’s search for methods that could be considered as complex in the code base.
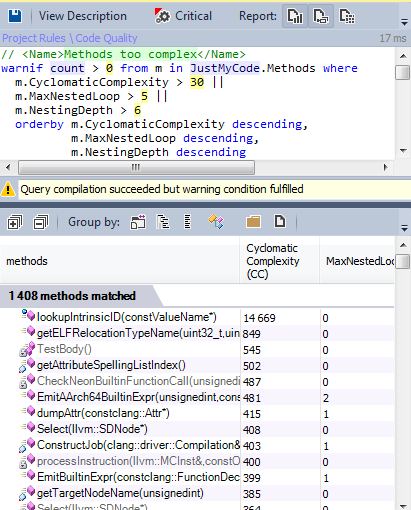
Only 1,5% are candidate to be refactored to minimize their complexity.
7-4 Halstead complexity
Halstead complexity measures are software metrics introduced by Maurice Howard Halstead in 1977. Halstead made the observation that metrics of the software should reflect the implementation or expression of algorithms in different languages, but be independent of their execution on a specific platform. These metrics are therefore computed statically from the code.
Many metrics was introduced by Halstead, Let’s take as example the TimeToImplement one, which represents the time required to program a method in seconds.
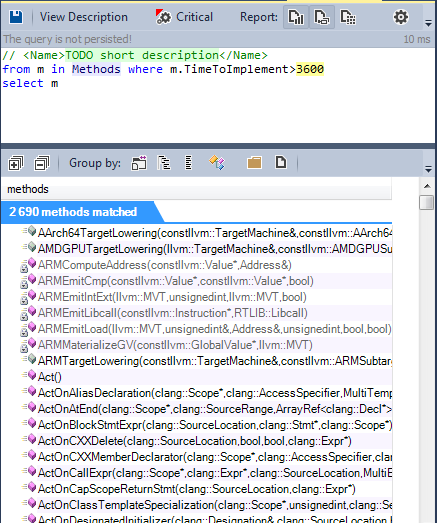
2690 methods require more than one hour to be implemented.
8- RTTI
RTTI refers to the ability of the system to report on the dynamic type of an object and to provide information about that type at runtime (as opposed to at compile time). However, RTTI become controversial within the C++ community. Many C++ developers chose to not use this mechanism.
What about the llvm/clang developers team?
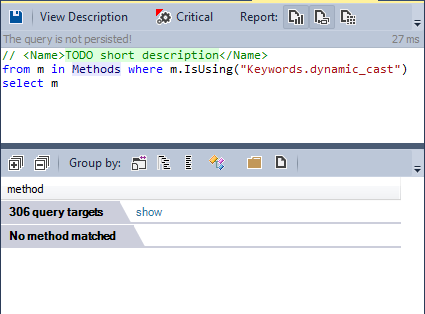
No method uses the dynamic_cast keyword, The llvm/clang team chose to not use the RTTI mechanism.
9- Exceptions
Exception handling is also another controversial C++ feature. Many known open source C++ projects not use it.
Let’s search if in the source code an exception was thrown.
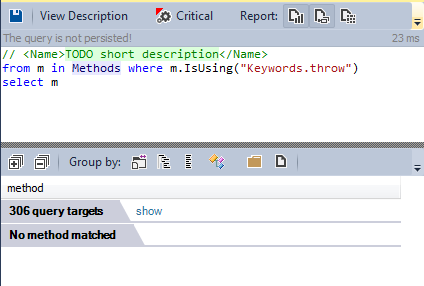
As the RTTI, the exceptions mechanism is not used.
10- Some statistics
10-1 most popular types
It’s interesting to know the most used types in a project, indeed these types must be well designed, implemented and tested. And any change to them could impact the whole project.
We can find them using the TypesUsingMe metric:
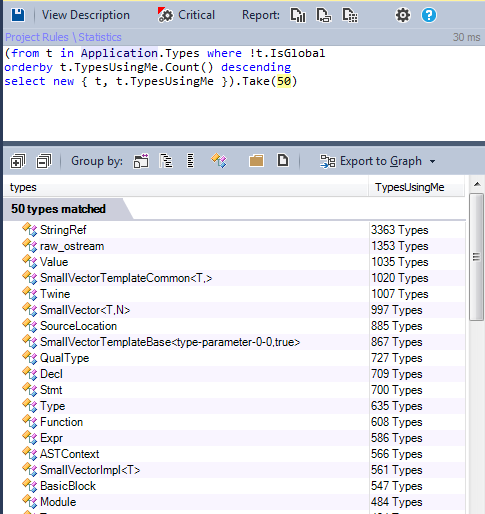
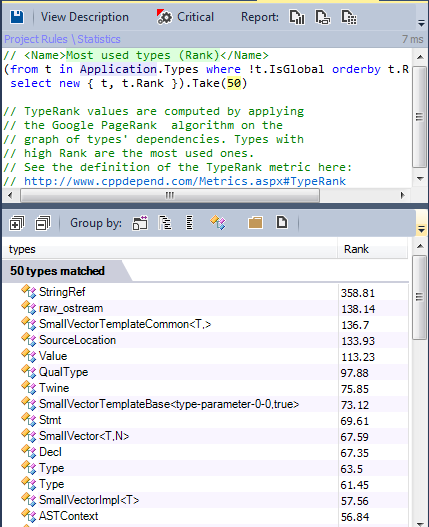
However There’s another interesting metric to search for popular types: TypeRank.
TypeRank values are computed by applying the Google PageRank algorithm on the graph of types’ dependencies. A homothety of center 0.15 is applied to make it so that the average of TypeRank is 1.
Types with high TypeRank should be more carefully tested because bugs in such types will likely be more catastrophic.
Here’s the result of all popular types according to the TypeRank metric:
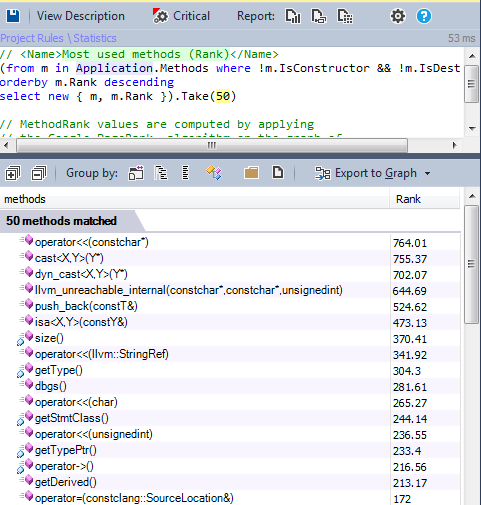
10-2 Most popular methods
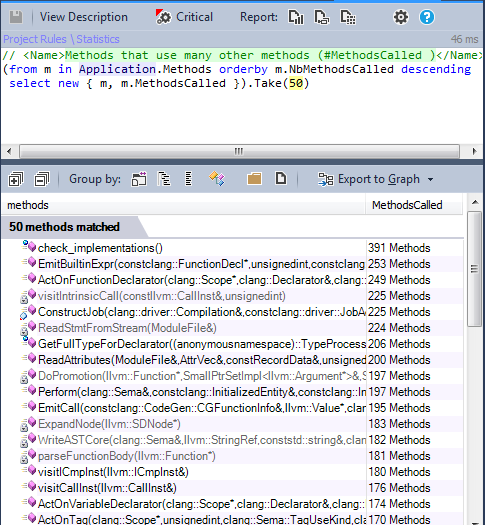
10-3 Methods calling many other methods
It’s interesting to know the methods using many other ones, It could reveal a design problem in these methods. And in some cases a refactoring is needed to make them more readable and maintanble.
Summary
The llvm/clang is very well designed and implemented, and as any other project, some refactoring could be acheived to improve it. In this post we discovered some minor possibe changes to do in the source code. Don’t hesitate to explore it’s source code to improve your C++ skills.