

OpenCV (Open Source Computer Vision) is a library of programming functions mainly aimed at real-time computer vision, developed by Intel Russia research center in Nizhny Novgorod. The library is cross-platform. It focuses mainly on real-time image processing.
OpenCV is widely used, Adopted all around the world, for end users, it’s very mature and powerful, for developers it’s well implemented and designed. The OpenCV developers used very basic principles which makes it very simple to understand and maintain.
Let’s discover some OpenCV design choices:
Modularity
1- Library based architecture
A library-based architecture makes the reuse and integration of functionality provided more flexible and easier to integrate into other projects.In addition, the library based architecture encourages clean APIs and separation. Therefore making it easier for developers to understand, since they only have to understand small pieces of the big picture.
OpenCV adopt this approach and defines many libraries, each one has a specific responsibility and all of them uses the opencv_core library.
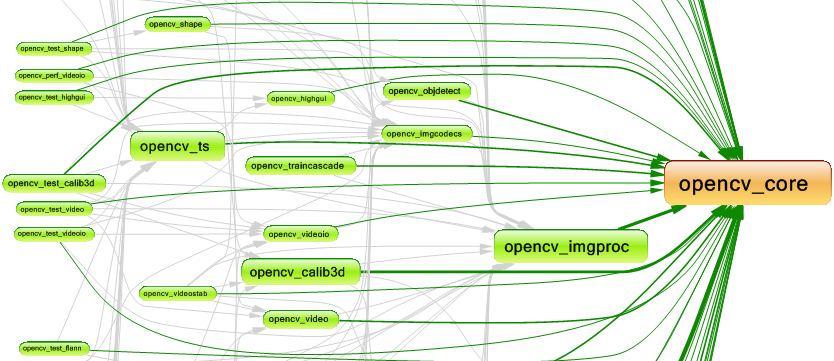
2- Modularize by namespaces
OpenCV uses widely namespaces to modularize its code base, here are for example the namespaces of the opencv_core project:
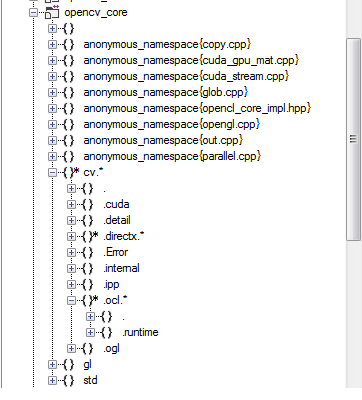 OpenCV uses the “Namespace-by-feature” approach. Namespace-by-feature uses namespaces to reflect the feature set. It places all items related to a single feature (and only that feature) into a single namespace. This results in namespaces with high cohesion and high modularity, and with minimal coupling between namespaces. Items that work closely together are placed next to each other.
OpenCV uses the “Namespace-by-feature” approach. Namespace-by-feature uses namespaces to reflect the feature set. It places all items related to a single feature (and only that feature) into a single namespace. This results in namespaces with high cohesion and high modularity, and with minimal coupling between namespaces. Items that work closely together are placed next to each other.
In case of OpenCV the namespaces are used for three main reasons:
- Modularize the libraries.
- Hide details like for “cv::detail” namespace, this approach could be very interesting if we want to inform the library user that he doesn’t need to use directly types inside this namespace and it’s only for internal use. For C# the “internal” keyword did the job, but in C++ there’s no way to hide public types to the library user.
- Anonymous namespace: namespace with no name. It avoids making global static variable. The “anonymous” namespace you have created will only be accessible within the file you created it in.
[adrotate banner=”3″]
Defines data model as POD types
Each project has its data model, it’s recommended to defines these data as POD types.
Let’s search in the OpenCV code base for structs with no methods and having only fields. For that CQLinq will be used to query the code base.
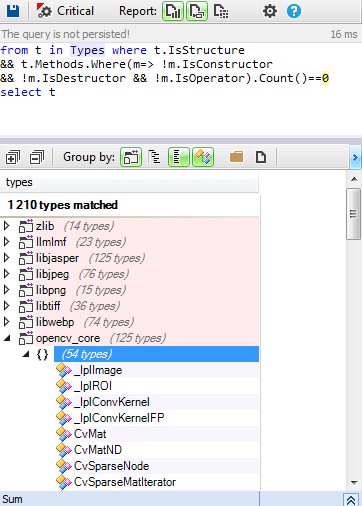
The result of this query concern 25% of the number of types defined in OpenCV projects. OpenCV defines almost all its data model in structs with only fields.
Avoid multiple inheritance
Using multiple inheritance could complicate the design, debuggers can have a hard time with it, therefore it’s not recommended by many C++ experts.
Let’s search which classes inherit from more than one concrete base class in the OpenCV code base.
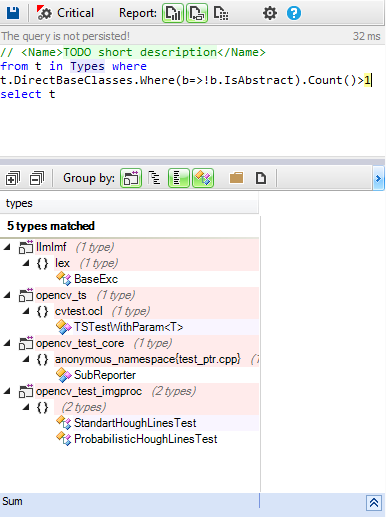
Only a few classes from test projects use the multiple inheritance, this concept is avoided in the whole OpenCV code base.
Avoid defining complex functions
Many metrics exist to detect complex functions, NBLinesOfCode, Number of parameters and number of local variables are the basic ones.
There are other interesting metrics to detect complex functions:
- Cyclomatic complexity is a popular procedural software metric equal to the number of decisions that can be taken in a procedure.
- Nesting Depth is a metric defined on methods that is relative to the maximum depth of the more nested scope in a method body.
- Max Nested loop equals the maximum level of loop nesting in a function.
The max value tolerated for these metrics depends more on the team choices, there are no standard values.
Let’s search for methods that could be considered as complex in the OpenCV code base.
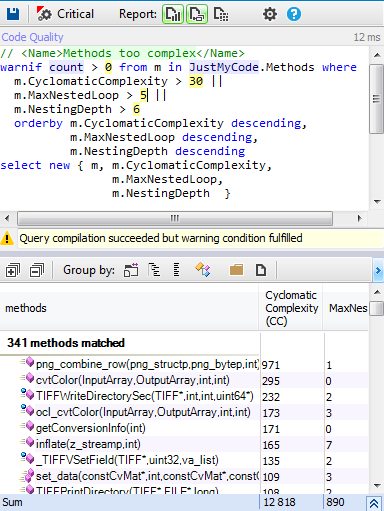
Only 1% is a candidate to be refactored to minimize their complexity.
Coupling
Low coupling is desirable because a change in one area of an application will require fewer changes throughout the entire application. In the long run, this could alleviate a lot of time, effort, and cost associated with modifying and adding new features to an application.
Low coupling could be achieved by using abstract classes. Here are three key benefits derived from using them:
- An abstract class provides a way to define a contract that promotes reuse. If an object implements an abstract class then that object is to conform to a standard. An object that uses another object is called a consumer. An abstract class is a contract between an object and its consumer.
- An abstract class also provides a level of abstraction that makes programs easier to understand. abstract class allows developers to start talking about the general way that code behaves without having to get into a lot of detailed specifics.
- An abstract class enforces low coupling between components, what’s make easy to protect the abstract class consumer from any implementation changes in the classes implementing the abstract classes.
Let’s search for all abstract classes defined by OpenCV :
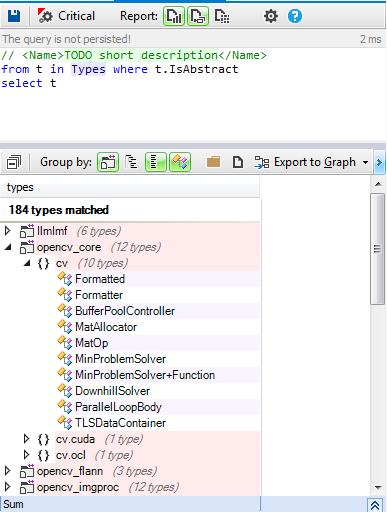
If our primary goal is to enforce low coupling, there’s a common mistake when using abstract classes, that could kill the utility of using them. It’s the using of the concrete classes instead of abstract ones, to explain better this problem let’s take the following example:
The class A implements the abstract class IA which contains the calculate() method, the consumer class C is implemented like this
public class C
{
….
public:
void calculate()
{
…..
m_a->calculate();
….
}
A* m_a;
};
The class C instead of referencing the abstract class IA, it references the class A, in this case, we lose the low coupling benefit, this implementation has two major drawbacks:
- If we decide to use another implementation of IA, we must change the code of C class.
- If some methods are added to A not existing in IA, and C use them, we also lose the contract benefit of using interfaces.
C# introduced the explicit interface implementation capability to the language to ensure that a method from the IA will be never called from a reference to concrete classes, but only from a reference to the interface. This technique is very useful to protect developers from losing the benefit of using interfaces.
Cohesion
The single responsibility principle states that a class should not have more than one reason to change. Such a class is said to be cohesive. A high LCOM value generally pinpoints a poorly cohesive class. There are several LCOM metrics. The LCOM takes its values in the range [0-1]. The LCOM HS (HS stands for Henderson-Sellers) takes its values in the range [0-2]. A LCOM HS value highest than 1 should be considered alarming. Here are to compute LCOM metrics:
LCOM = 1 – (sum(MF)/M*F)
LCOM HS = (M – sum(MF)/F)(M-1)
Where:
- M is the number of methods in class (both static and instance methods are counted, it includes also constructors, properties getters/setters, events add/remove methods).
- F is the number of instance fields in the class.
- MF is the number of methods of the class accessing a particular instance field.
- Sum(MF) is the sum of MF overall instance fields of the class.
The underlying idea behind these formulas can be stated as follow: a class is utterly cohesive if all its methods use all its methods use all its instance fields, which means that sum(MF)=M*F and then LCOM = 0 and LCOMHS = 0.
LCOMHS value higher than 1 should be considered alarming.
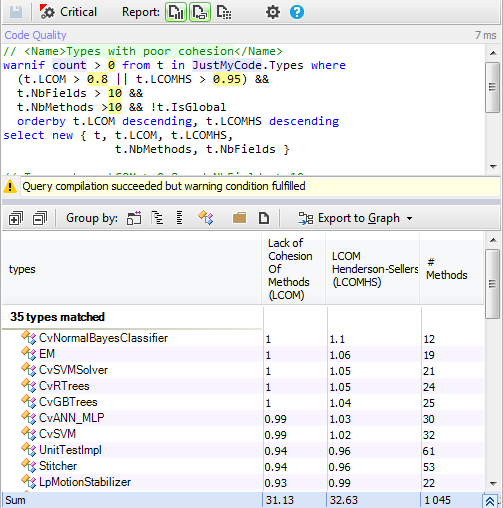
Only a few types are not cohesive.
Conclusion
If you take a look at the OpenCV source code, you will be surprised by the simplicity of its implementation, no advanced design concepts are used, no over-engineering, just some basic principles applied.
[adrotate banner=”3″]