“A picture is worth a thousand words” is an English idiom. It refers to the notion that a complex idea can be conveyed with just a single still image or that an image of a subject conveys its meaning or essence more effectively than a description does.
This idiom could also be applied in software programming. Indeed you can easilly understand a mini project when exploring its source code. However a big project become complex and not easy to understand. In such cases it’s better to visualize the source code using graphs and diagrams to assist the developers understanding the source code.![]()
Let’s discover some useful diagrams provided by CppDepend to understand the code base.
I-Treemap diagram:
Treemapping is a method for displaying tree-structured data by using nested rectangles. The tree structure used in CppDepend treemap is the usual code hierarchy:
- C/C++ projects contain namespaces,
- Namespaces contain types,
- Types contains methods and fields.
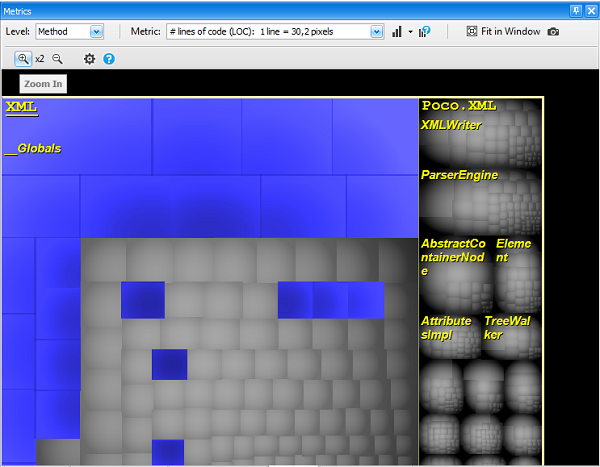
With treemap rectangles represent code elements. The option level determines the kind of code element represented by unit rectangles. The option level can take the 5 values: project, namespace, type, method and field. The two screenshots below shows the same code base represented through type level on left, and namespace level on right. 
The option Code Metric of the treemap determines the size of rectangles. For example if level is set to type and metric is set tonumber of Lines of Code, each unit rectangle represents a type, and the size of a unit rectangle is proportional to the number of Lines of Code of the corresponding type.
If a CQLinq query is currently edited, the set of code elements matched by the query is shown on the treemap as a set of blue rectangles. In the screenshot below, a CQLinq query matches the 200 largest methods. Here the treemap level is method and the metric is number of lines of code. As expected, we can see that blue rectangles represent the 200 largest unit rectangles of the treemap.
The screenshot below also shows that the currently pointed code element (here the project XML) is shown as a red rectangles on the treemap. 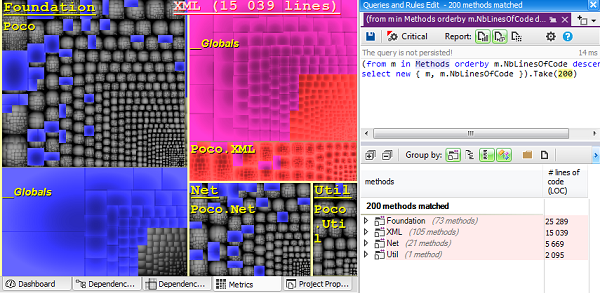
Common Scenarios
By choosing an appropriate combination of metric and level values, the Metric View helps see patterns that would be hard to spot with other ways.
Too Big, Too Complex
CppDepend provides many code metrics to spot too big and too complex code. Method with too many parameters, too many variables, too many lines of code, too high cyclomatic complexity etc… should be banished. The same way types with too many lines of code should be banished too.
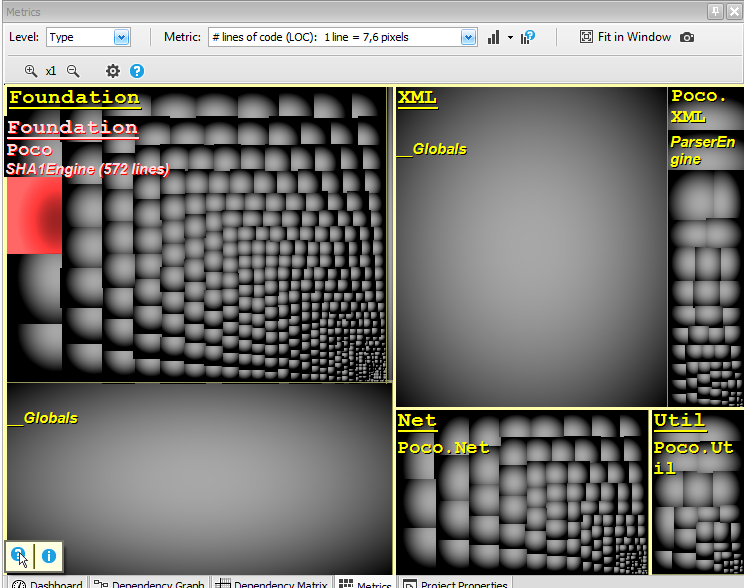
On the screenshot below, the treemap level is set to type and the metric is number of lines of code. Large rectangles represent large types of the code base. Hovering a rectangle with the mouse indicates the type metric values, here the type number of lines of code. Clearly, code treemaping helps not only spotting too large and too complex code elements, but also, it helps comparing their respective size and complexity.
Flaws Localization
In the screenshot below we are asking with a CQLinq query, for methods with too many parameters and too many variables. Blue rectangles show matched methods on the treemap. Here the interesting point is that some matched methods seem to be grouped. Because treemap is a hierarchical view, if a set of code elements is grouped, it means that the code elements belong to the same parent. And indeed, here the 12 methods grouped belong to the same type.
Spotting the parent types of these 12 methods would have been hard without treemaping. Now the code quality reviewer can focus his attention on this region that seems to contain more flaws than other part of the code base.
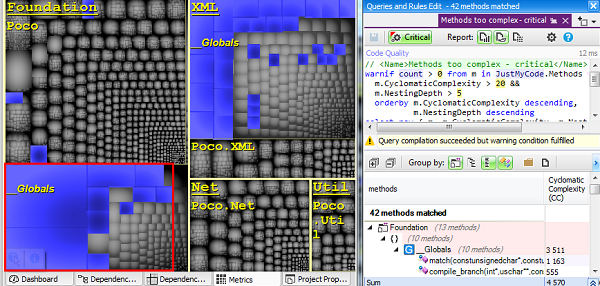
Top-Down Code Exploration
The CppDepend treemap metric view supports zoom-in and zoom-out. This makes easy to zoom on a particular project, namespace or class. This can be especially useful to explore and compare the volume of components in terms of lines of code.
By no mean productivity should be measured in terms of lines of code. However counting lines of code has been proven to be a useful metric to accurately estimate software, given a certain context of an organization. The code base features are somehow partitioned into assemblies, namespaces and types. With treemaping, these artifacts become rectangles that sit side-by-side. Rectangles areas, hence features weight, can be compared visually. Being able to periodically explore code size through treemaping is a unique way to build an accurate sense of feature weight and feature cost.
Do the experiment to visualize treemap on a code base you know well, and you’ll be surprised to discover unexpected feature size.
Code Structure Observations
Choosing to use the Metric View with a metric different than volume (lines of code, number of parameters for methods…) or complexity, can reveal interesting observations.
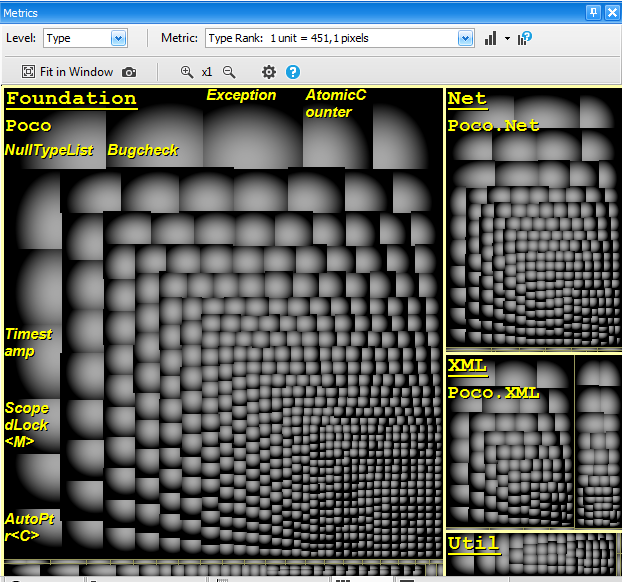
The ranking metric is a code metric that measure the popularity of a type or a method in a code base. Using treemaping with the ranking metric gives a clear view of where popular types are declared. This quickly gives information about what is important in the code base.
The screenshot below shows types of the Microsoft DLR (Dynamic language Runtime) code base treemaped with the ranking metric. The treemap indicates that CallSite and Expression are popular concepts of the DLR, and this is indeed the case.
The same kind of interesting Code Structure Observations can be made with code metrics such as Afferent/Efferent coupling or Level.
II- Dependency Graph
CppDepend offers a wide range of facilities to help user exploring an Existing Code Architecture using the dependency grapj. here are some most popular Code Exploration scenarios:
Call Graph
CppDepend can generate any call graph you might need with a two steps procedure.
- First: Ask for direct and indirect callers/callees of a type, a field, a method, a namespace or a project. The effect is that the following CQLinq query is generated to match all callers or callees asked.
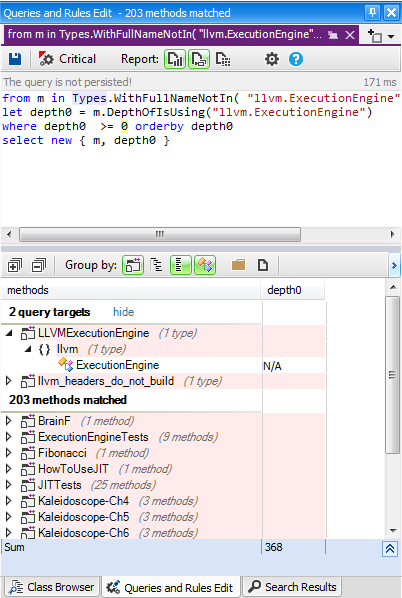
- Notice that, in the CQLinq query result, the metric DepthOfIsUsing/DepthOfIsUsedBy shows depth of usage (1 means direct, 2 means using a direct user etc…). The CQLinq query can easily be modified to only match indirect callers/callees with a certain condition on depth of usage.Notice also that callers/callees asked are not necessarily of the same kind of the concerned code element. For example here we ask for methods that are using directly or indirectly a type.
- Second: Once the CQLinq query matches the set of callers/callees that the user wishes, the set of matches result can be exported to the Dependency Graph. This has for effect to show the call graph wished.
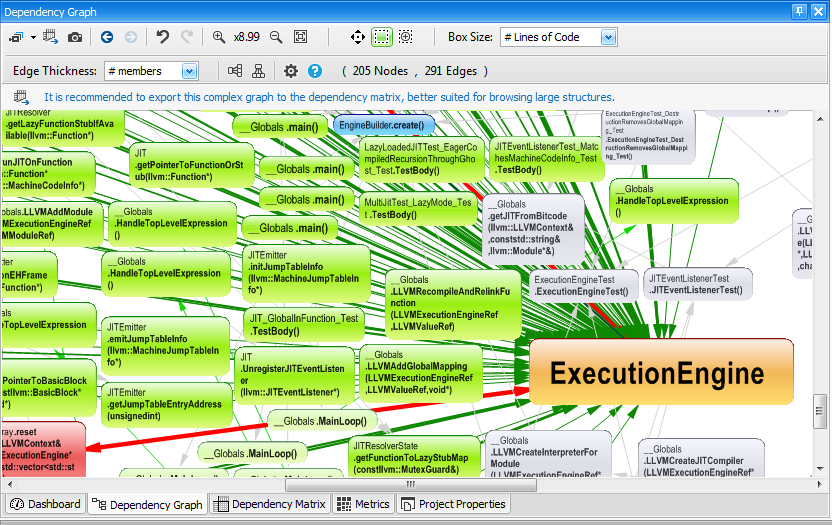
Class Inheritance Graph
To display a Class of Inheritance Graph, the same two steps procedure shown in the precedent section (on generating a Call Graph) must be applied.
- First: Generate a CQLinq query asking for the set of classes that inherits from a particular class (or that implement a particular interface). Here, the following CQLinq query is generated:
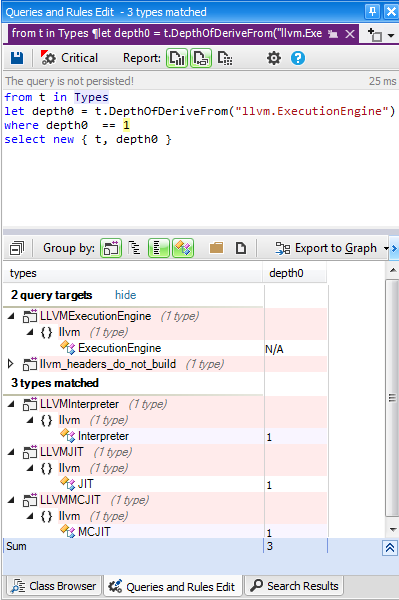
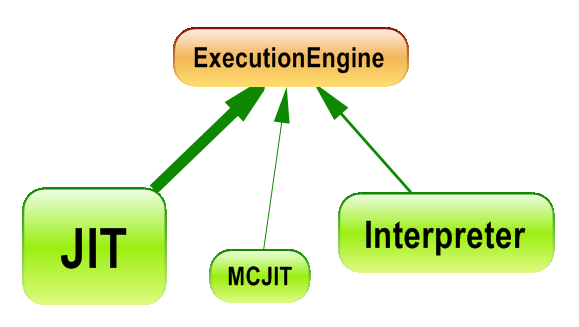
- Second: Export the result of the CQLinq query to the Dependency Graph to show the inheritance graph wished.
Coupling Graph
It might be needed to know which code elements exactly are involved in a particular dependency. Especially when one needs to anticipate the impact of a structural change. In the screenshoot below, the CppDepend Info panel describes a coupling between 2 projects.
From pointing a cell in the dependency matrix, it says that X types of an project A are using Y types of an project B. Notice that you can change the option Weight on Cell to # methods, # members or # namespaces, if you need to know the coupling with something else than types.
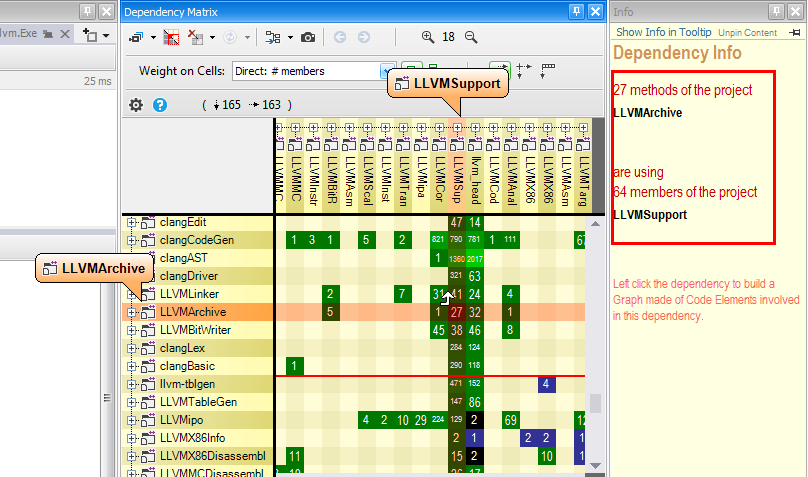
Just left clicking the matrix cell shows the coupling graph below.
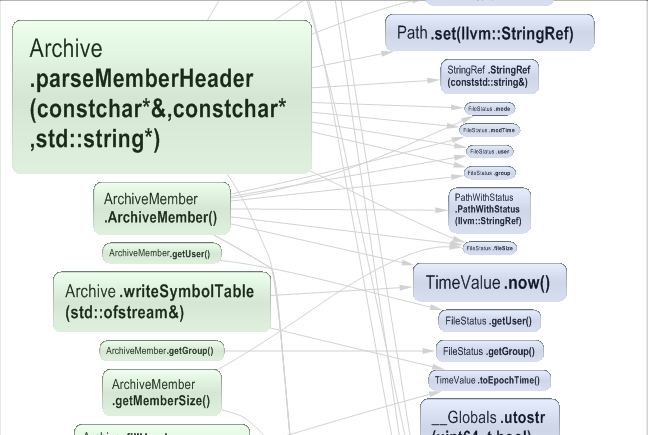
A coupling graph can also be generated from an edge in the dependency graph. Here, you can adjust the option Edge Thickness to something else than # type.
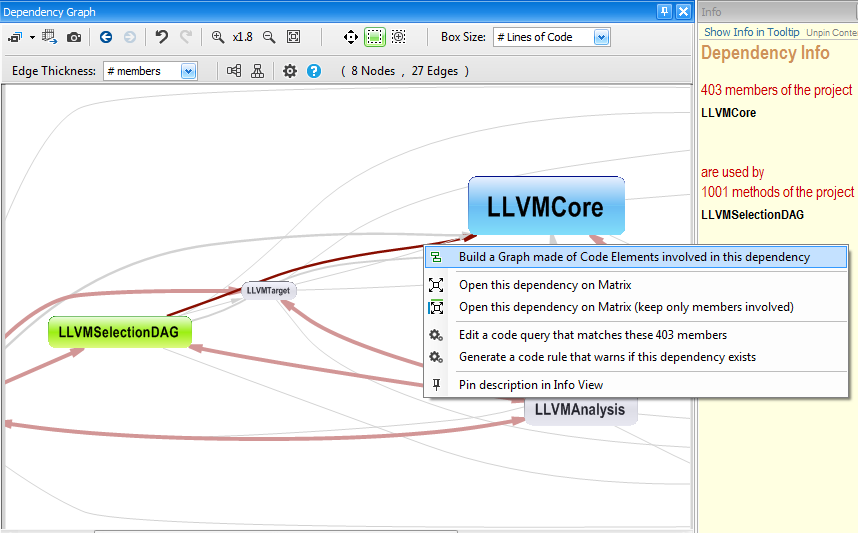
Path Graph
If you wish to dig into a path or a dependency cycle between 2 code elements, the first thing to do is to show the dependency matrix with the option Weight on Cells: Direct & indirect depth of use.
Matrix blue and green cells will represent paths while black cells will represent dependency cycles. For example, here, the Info panel tells us that there is a path of minimal length 7 between the 2 types involved.
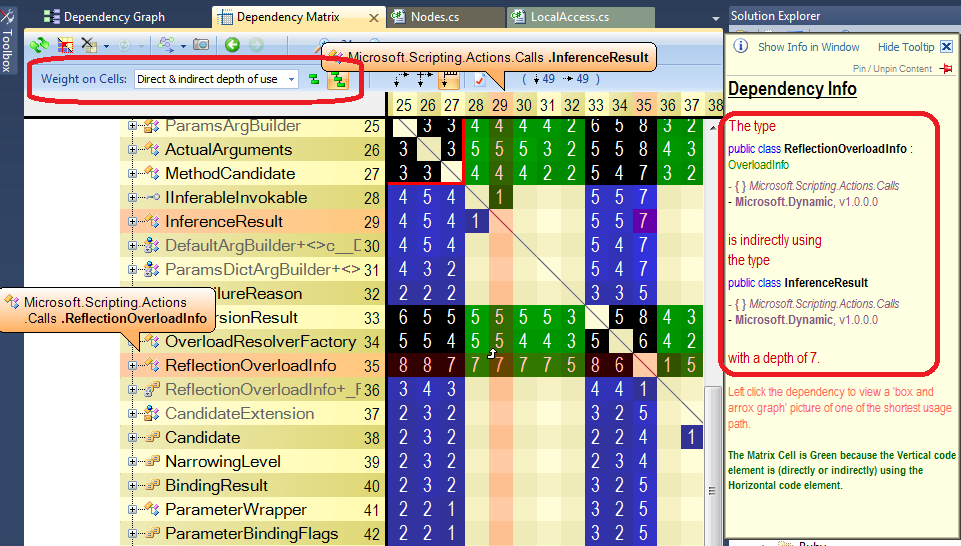
Just left clicking the cell shows the path graph below.
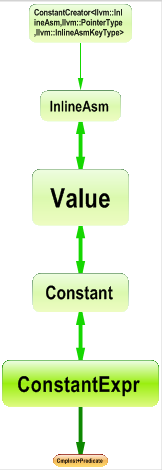
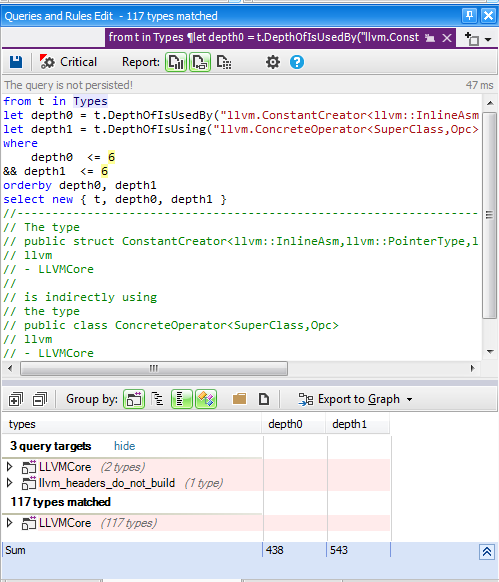
All Paths Graph
In certain situations, you’ll need to know about all paths from a code element A to a code element B. For example, here, the Info panel tells us that there is a path of minimal length 2 between the 2 types involved.
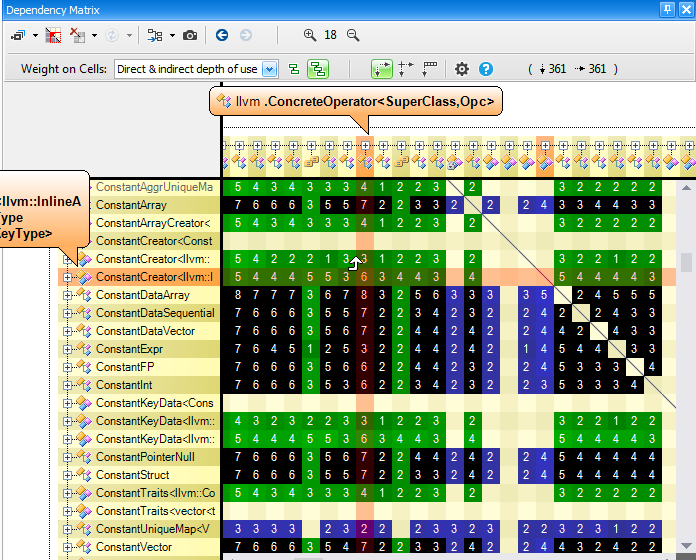
Finally exporting to the graph the 12 types matched by the CQLinq query, shows all paths from A to B.

Cycle Graph
As we explained in the previous section, to deal with dependency cycle graphs, the first thing to do is to show the dependency matrix with the option Weight on Cells: Direct & indirect depth of use. Black cells then represent cycles.
For example, here, the Info panel tells us that there is a dependency cycle of minimal length 5 between the 2 types involved.
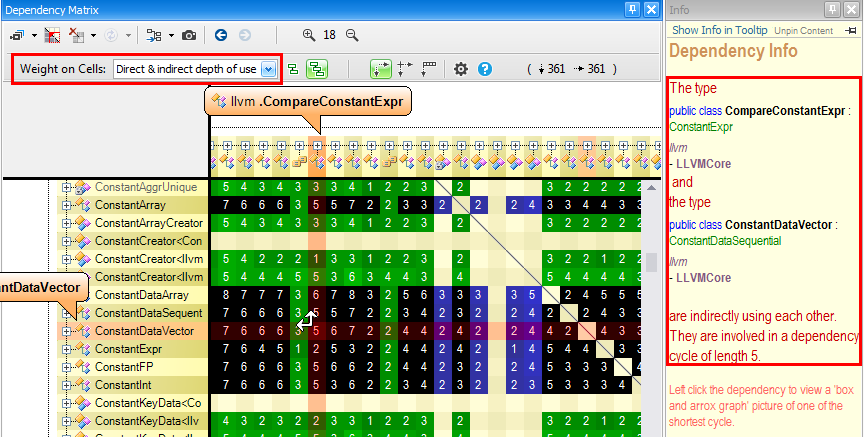
Just left clicking the cell shows the cycle graph below.
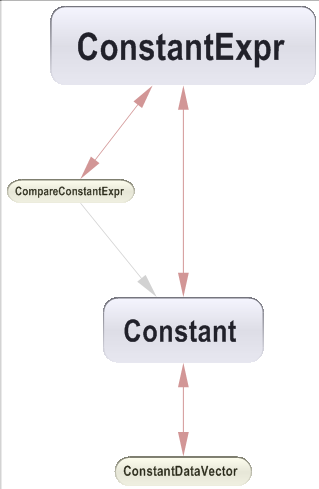
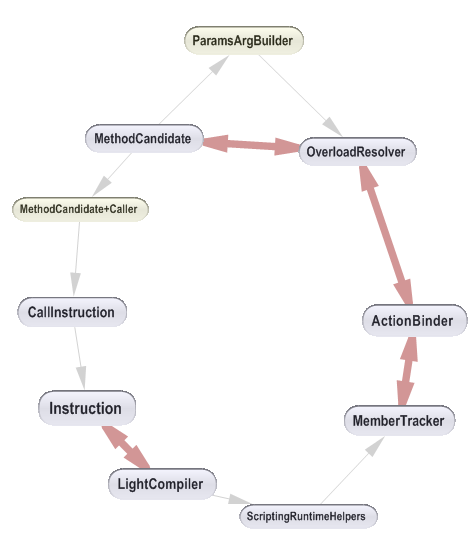
We’d like to warn that obtaining a clean ’rounded’ dependency cycle as the one shown above, is actually more an exceptional situation than a rule.
Often, exhibiting a cycle will end up in a not ’rounded’ graph as the one shown below. In this example, the minimal length of a cycle between the 2 types involved (in yellow) is 12. Count the number of edges crossed from one yellow type to the other one, and you’ll get 12. You’ll see that some edges will be counted more than once.
III – Dependency Structure Matrix
Large Graph visualized with Dependency Structure Matrix
Here, we’d like to underline the fact that when the dependency Graph becomes unreadable, it is worth switching to the dependency Matrix.
Both dependency Graph and dependency Matrix co-exist because:
- Dependency Graph is intuitive but becomes unreadable as soon as there are too many edges between nodes.
- Dependency Matrix requires time to be understood, but once mastered, you’ll see that the Dependency Matrix is much more efficient than the Dependency Graph to explore an existing architecture. More information on the Dependency Matrix readability can be found in Identify Code Structure Patterns at a Glance
To illustrate the point, find below the same dependencies between 77 namespaces shown through Dependency Graph and Dependency Matrix.
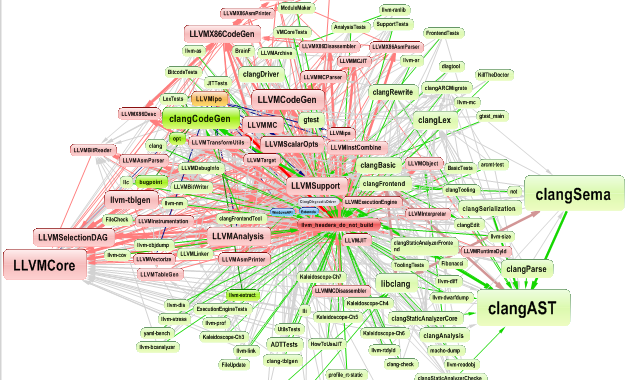
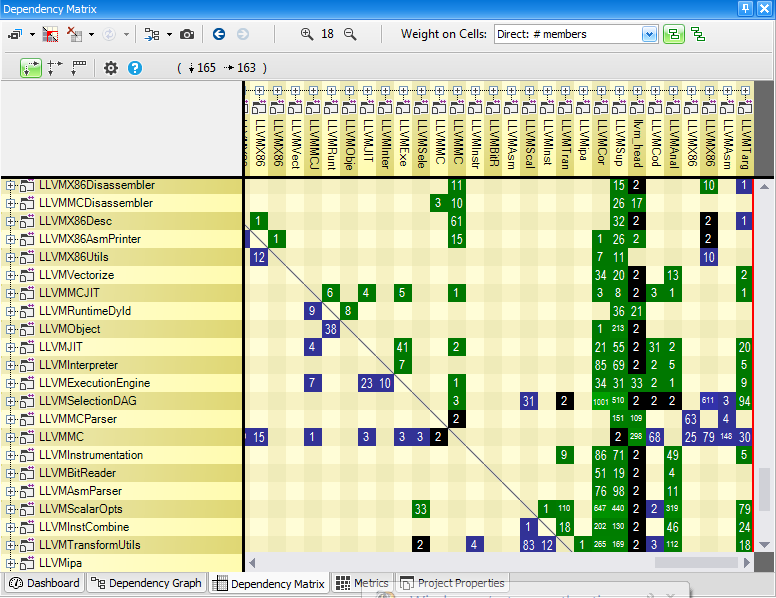
The DSM (Dependency Structure Matrix) is a compact way to represent and navigate across dependencies between components. For most engineers, talking of dependencies means talking about something that looks like that:
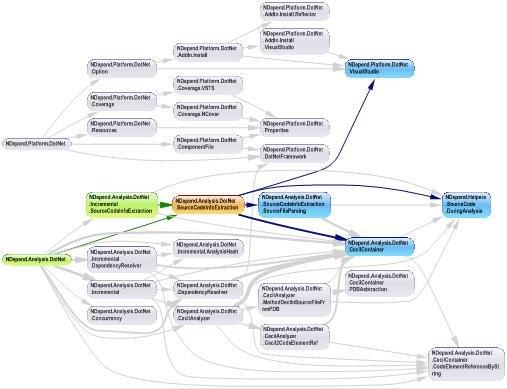
DSM is used to represent the same information than a graph.
- Matrix headers’ elements represent graph boxes
- Matrix non-empty cells correspond to graph arrows.
As a consequence, in the snapshot below, the coupling from Net to Foundation is represented by a non empty cell in the matrix and by an arrow in the graph.
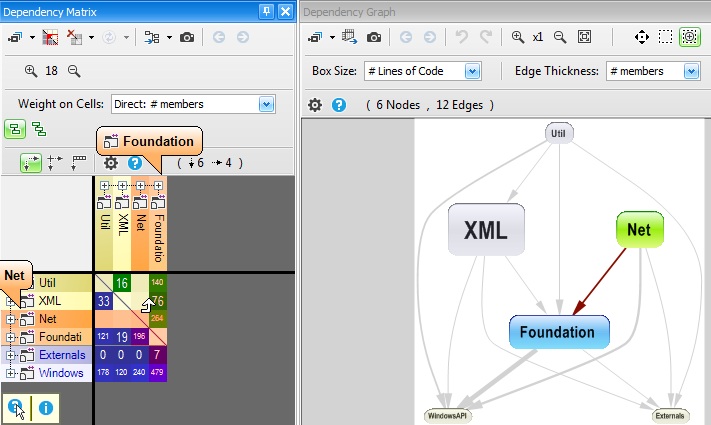
Why using two different ways, graph and DSM, to represent the same information? Because there is a trade-off:
- Graph is more intuitive but can be totally not understandable when the numbers of nodes and edges grow (a few dozens boxes can be enough to produce a graph too complex)
- DSM is less intuitive but can be very efficient to represent large and complex graph. We say that DSM scalescompare to graph.
Once one understood DSM principles, typically one prefers DSM over graph to represent dependencies. This is mainly because DSM offers the possibility to spot structural patterns at a glance. This is explained in the second half of the current document.
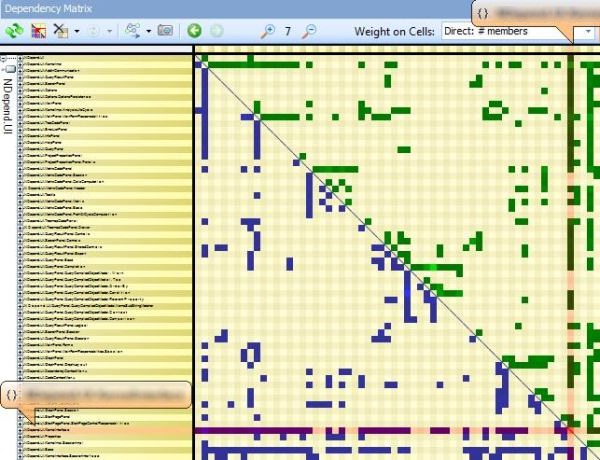
CppDepend offers Context-Sensitive Help to educate the user about what he sees on DSM. CppDepend’s DSM relies on a simple 3 coloring scheme for DSM cell: Blue, Green and Black. When hovering a row or a column with the mouse, the Context-Sensitive Help explains the meaning of this coloring scheme:
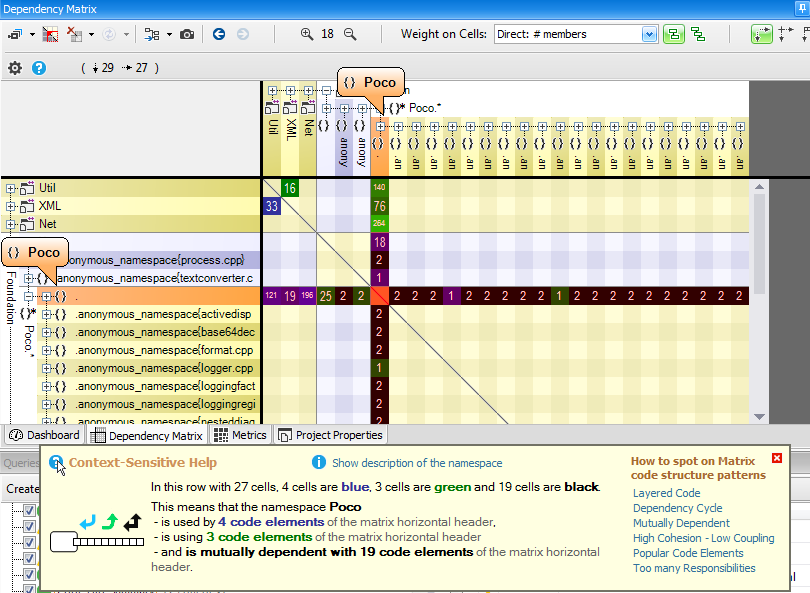
A non-empty DSM Cell contain a number. This number represent the strengths of the coupling represented by the cell. The coupling strength can be expressed in terms of number of members/methods/fields/types or namespaces involved in the coupling, depending on the actual value of the option Weight on Cells. In addition to the Context-Sensitive Help, the DSM offers as well a Info Panel that explains coupling with a plain-english description:
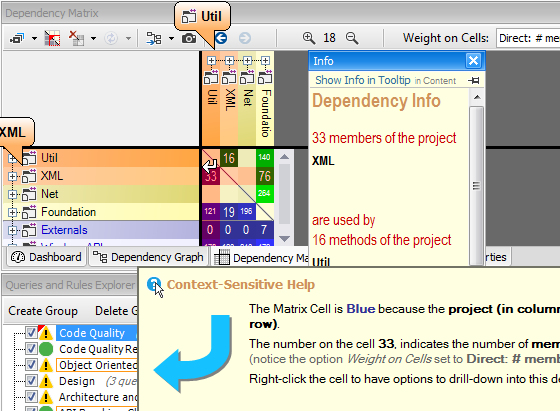
CppDepend’s DSM comes with numerous options to try:
- It has numerous facilities to dig into dependency exploration (a parent column/row can be opened, cells can be expanded…)
- It can deal with squared symmetric DSM and rectangular non-symmetric DSM
- Horizontal and Vertical headers can be bound, to constantly have a squared symmetric matrix
- It comes with the option Indirect usage, where cell shows direct and indirect usage
- The vertical header can contains tier code elements
- …
It is advised to experience all these features by yourself, by analyzing dependencies into your code base.
Identify Code Structure Patterns on Matrix
As explained in the introduction, DSM comes with the particularity to offer easy identification of popular Code Structure Patterns. Let’s present most common scenarios:
Layered Code
One pattern that is made obvious by a DSM is layered structure (i.e acyclic structure). When the matrix is triangular, with all blue cells in the lower-left triangle and all green cells in the upper-right triangle, then it shows that the structure is perfectly layered. In other words, the structure doesn’t contain any dependency cycle.
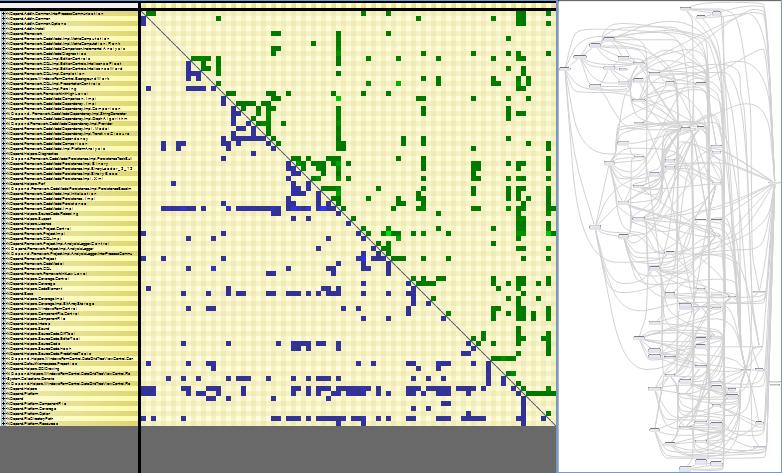
On the right part of the snapshot, the same layered structure is represented with a graph. All arrows have the same left to right direction. The problem with graph, is that the graph layout doesn’t scale. Here, we can barely see the big picture of the structure. If the number of boxes would be multiplied by 2, the graph would be completely un-readable. On the other side, the DSM representation wouldn’t be affected; we say that DSM scales better than graph.
Side note: Interestingly enough, most of graph layout algorithms rely on the fact that a graph is acyclic. To compute layout of a graph with cycles, these algorithms temporarily discard some dependencies to deal with a layered graph, and then append the discarded dependencies at the last step of the computation.
Dependency Cycle
If a structure contains a cycle, the cycle is displayed by a red square on the DSM. We can see that inside the red square, green and blue cells are mixed across the diagonal. There are also some black cells that represent mutual direct usage (i.e A is using B and B is using A).
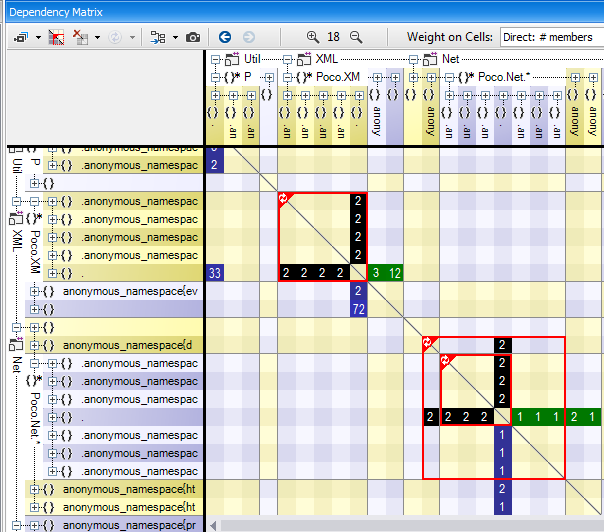
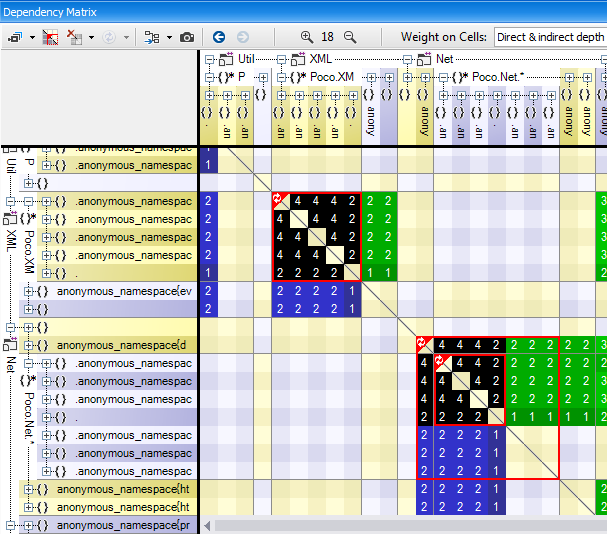
The CppDepend’s DSM comes with the unique option Indirect Dependency. An indirect dependency between A and B means that A is using something, that is using something, that is using something … that is using B. Below is shown the same DSM with a cycle but in indirect mode. We can see that the red square is filled up with only black cells. It just means that given any element A and B in the cycle, A and B are indirectly and mutually dependent.
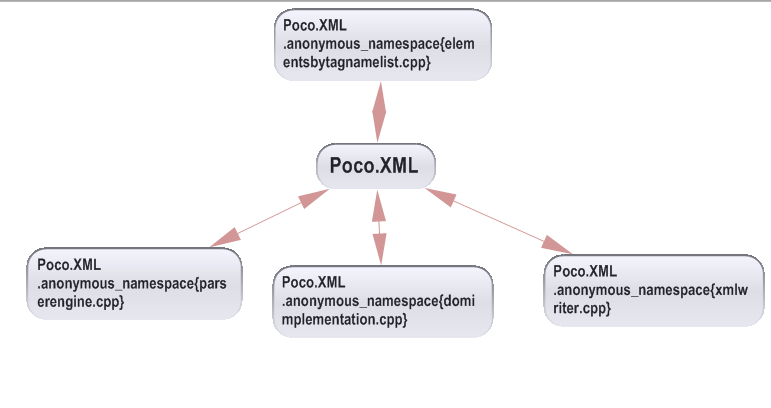
Here is the same structure represented with a graph. The red arrow shows that several elements are mutually dependent. But the graph is not of any help to highlight all elements involved in the parent cycle.
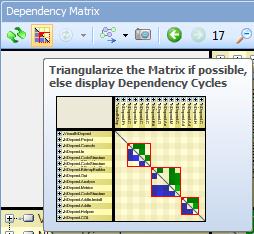
Notice that in CppDepend, we provided a button to highlight cycles in the DSM (if any). If the structure is layered, then this button has for effect to triangularize the matrix and to keep non-empty cells as closed as possible to the diagonal.
High Cohesion – Low Coupling
The idea of high-cohesion (inside a component) / low-coupling (between components) is popular nowadays. But if one cannot measure and visualize dependencies, it is hard to get a concrete evaluation of cohesion and coupling. DSM is good at showing high cohesion. In the DSM below, an obvious squared aggregate around the diagonal is displayed. It means that elements involved in the square have a high cohesion: they are strongly dependent on each other although. Moreover, we can see that they are layered since there is no cycle. They are certainly candidate to be grouped into a parent artifact (such as a namespace or an assembly).
On the other hand, the fact that most cells around the square are empty advocate for low-coupling between elements of the square and other elements.
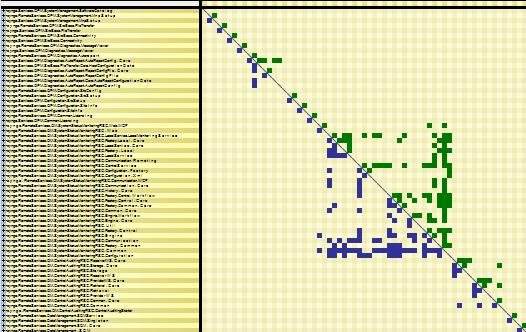
In the DSM below, we can see 2 components with high cohesion (upper and lower square) and a pretty low coupling between them.
While refactoring, having such an indicator can be pretty useful to know if there are opportunities to split coarse components into several more fine-grained components.
Too Many Responsibilities
The Single Responsibility Principle (SRP) is getting popular amongst software architects community nowadays. The principle states that: a class shouldn’t have more than one reason to change. Another way to interpret the SRP is that a class shouldn’t use too many different other types. If we extend the idea at other level (assemblies, namespaces and method), certainly, if a code element is using dozens of other different code elements (at same level), it has too many responsibilities. Often the term God class or God component is used to qualify such piece of code.
DSM can help pinpoint code elements with too many responsibilities. Such code element is represented by columns with many blue cells and by rows with many green cells. The DSM below exposes this phenomenon.

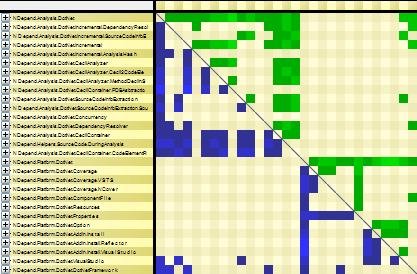
Popular Code Elements
A popular code element is used by many other code elements. Popular code elements are unavoidable (think of theString class for example) but a popular code element is not a flaw. It just means that in every code base, there are some central concepts represented with popular classes
A popular code element is represented by columns with many green cells and by rows with many blue cells. The DSM below highlights a popular code element.
Something to notice is that when one is keeping its code structure perfectly layered, popular components are naturally kept at low-level. Indeed, a popular component cannot de-facto use many things, because popular component are low-level, they cannot use something at a higher level. This would create a dependency from low-level to high-level and this would break the acyclic property of the structure.
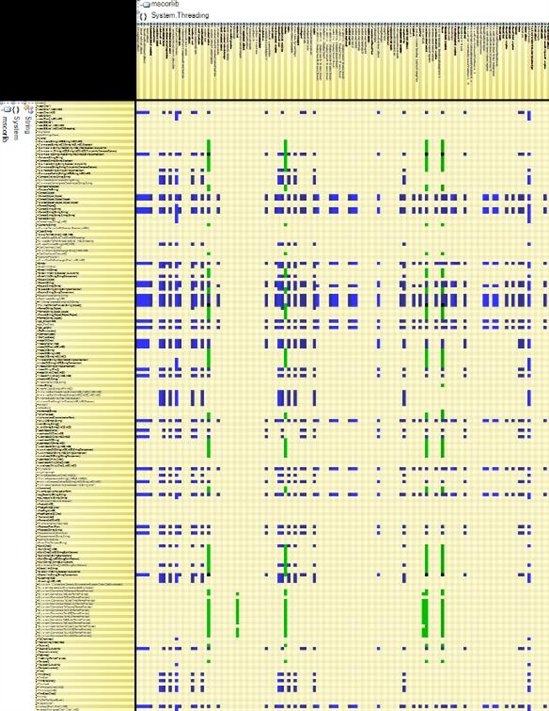
Mutually Dependent
You can see the coupling between 2 components by right clicking a non-empty cell, and select the menu Open this dependency.
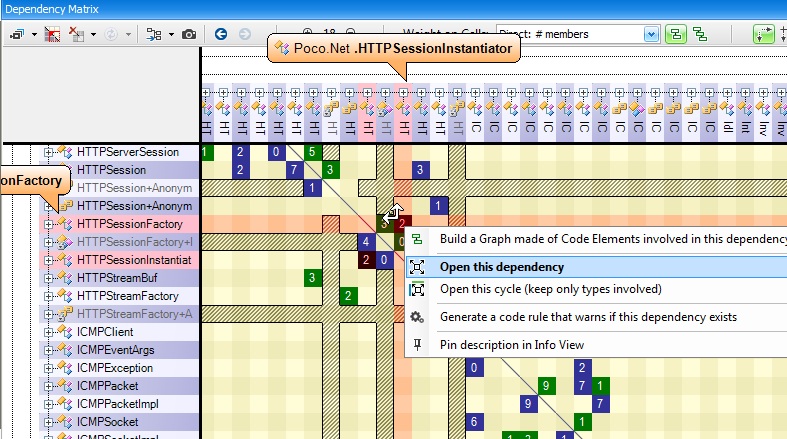
If the opened cell was black as in the snapshot above (i.e if A and B are mutually dependent) then the resulting rectangular matrix will contains both green and blue cells (and eventually black cells as well) as in the snapshot below.
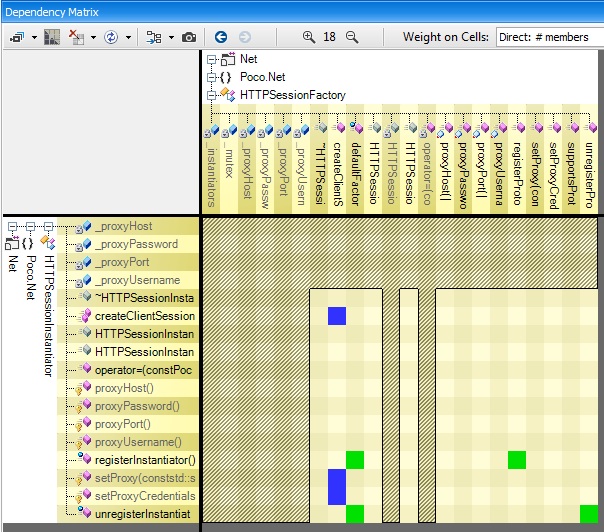
In this situation, you’ll often notice a deficit of green or blue cells (3 blue cells for 1 green cell here). It is because even if 2 code elements are mutually dependent, there often exists a natural level order between them. For example, consider the System.Threading namespaces and the System.String class. They are mutually dependent; they both rely on each other. But the matrix shows that Threading is much more dependent on String than the opposite (there are much more blue cells than green cells). This confirms the intuition that Threading is upper level than String.