

ChatGPT has gained popularity in recent times. As a team with years of experience in the field of code quality, we decided to experiment with ChatGPT and asked it to create a new software metric. Before executing the query, we had doubts about whether we would get a good result, or any result at all. We were concerned that the response might be along the lines of:
“Creating a new software metric requires extensive testing in real projects to demonstrate its reliability as an indicator for improving code quality.”
However, to our surprise, we received a metric 🙂
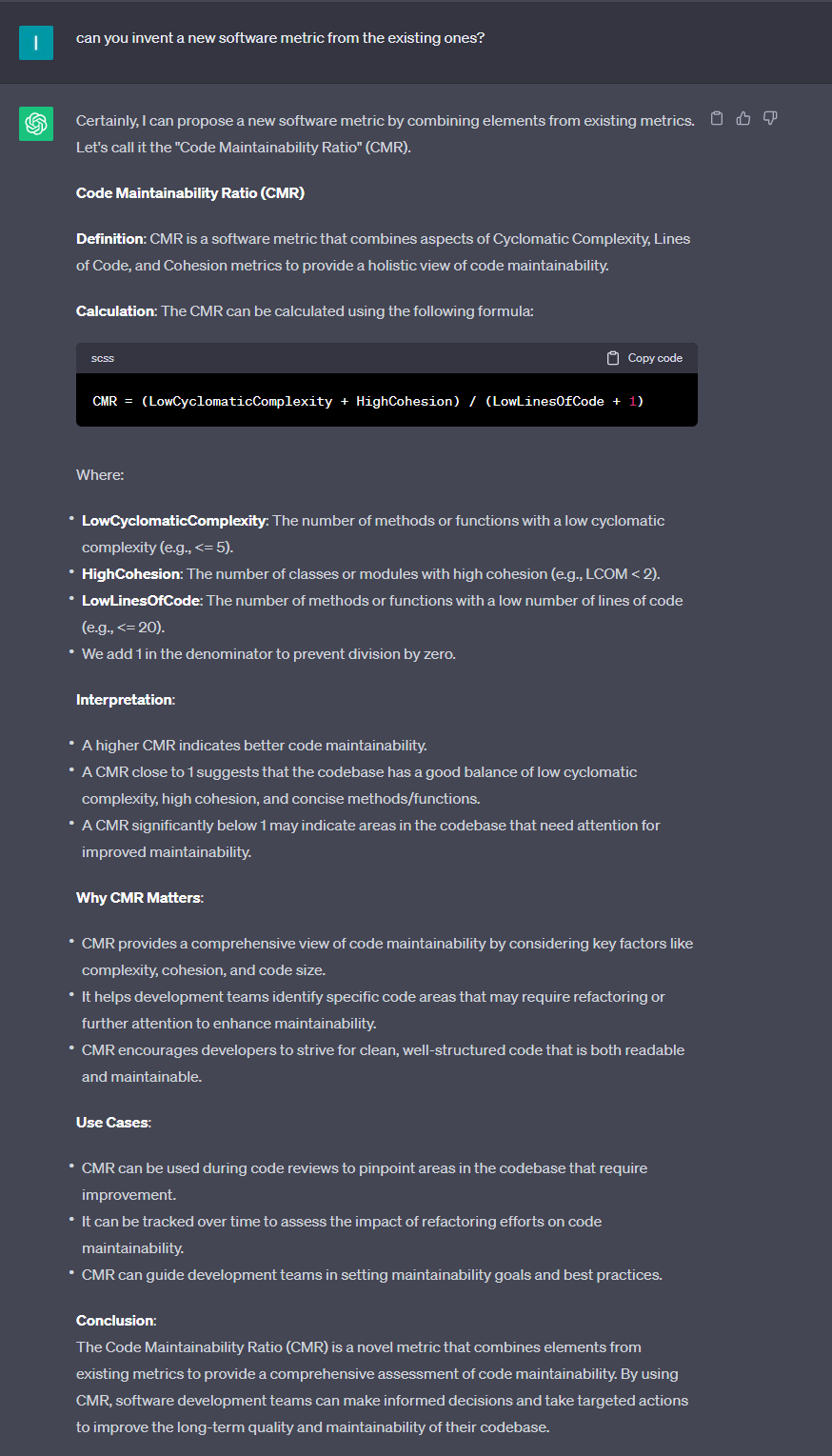
But is this metric truly reliable as an indicator for maintainability?
Let’s analyze the formula: `lowCyclomaticComplexity + HighCohesion`
Our thought process behind this formula is as follows:
– Maintainability depends on the complexity of the methods.
– Maintainability also depends on the cohesion of the types.
– There’s no direct correlation between cyclomatic complexity and cohesion, which is why we used the `+` operator in the formula.
– To obtain a reliable result, it’s better to use a ratio that takes code size into account.
At first glance, this formula seems promising. However, in real projects, there’s a significant issue with this formula, particularly regarding the statement:
“There’s no direct correlation between cyclomatic complexity and cohesion.”
In such cases, we need to check if these two metrics are closely related or if one metric consistently exceeds the other. If one metric consistently dominates the other, it may render the metric irrelevant. In our case, the `lowComplexity` metric could be much higher compared to the cohesion metric, potentially overshadowing it and making the overall metric less meaningful.
To improve this metric, we can introduce additional operators like natural logarithms, multiplication, division, or other mathematical functions to refine the formula and achieve a more reliable result, much like what’s done with the Maintainability Index:
`Maintainability Index = 171 – 5.2 * ln(Halstead Volume) – 0.23 * (Cyclomatic Complexity) – 16.2 * ln(Lines of Code)`
How do we refine software metric formulas?
There’s no magic involved; it requires extensive testing in real projects and working with these metrics over months or even years to identify the factors or operators that lead to a reliable metric.
Conclusion:
It’s essential to remember that ChatGPT and AI, in general, are valuable tools but won’t replace human expertise any time soon. Human validation and oversight are critical in all fields. So, don’t worry; AI won’t take your job; it will assist you in doing it better.